


Deliver Video Transformation With Confidence
Beamr VISTA closes the gap between fast but limited objective metrics and reliable but unscalable subjective testing In broadcasting, encoding…

Beamr’s ML-Safe Video Compression Validated on NVIDIA Cosmos Curator
ML-Safe Testing Series, Part 4: 41%–57% file size reduction with no measurable impact on AV captioning for Cosmos Curator outputs Ronen…
From Uncertainty to Confidence: ML-Safe Video Data Compression for Physical AI Systems
How content-adaptive compression, accelerated by NVIDIA, addresses video data bottlenecks for physical AI pipelines, including autonomous…

Deep Dive: Managing the Petabyte-Scale AV Video Data Bottlenecks
ML-Safe Testing Series, Part 3: Optimized video data processing for AV – 20%-50% file size reduction with remarkable detection,…

ML-Safe AV Video Data Processing Achieves Up to 50% Storage Reduction
ML-Safe Testing Series, Part 2: Benchmark testing shows how AV developers can achieve greater savings across storage, networking and compute…

From 720p to 4K in Real-Time: CDN-Friendly Video Pipeline Powered by NVIDIA
Live sports broadcasters can deliver 4K experiences from 720p sources. The high-efficiency solution enables to reduce CDN costs by up to 50%…

Unlocking New Value from Media Archives with Modernized and Optimized Cloud Migration
The Challenge: A Decades-Old Burden For tier-1 broadcasters, a major constraint is their decades-old media archive, often spanning hundreds of…
Beamr is Pushing the Boundaries of AV Data Efficiency, Accelerated by NVIDIA
Designed to protect visual fidelity, Beamr’s solution helps address the infrastructure challenges associated with autonomous vehicle…

How Content-Adaptive Video Compression Tackles Autonomous Vehicle Data Explosion
By Ronen Nissim and Tamar Shoham Overview The explosion of video data in autonomous vehicles (AVs) systems presents a critical challenge to…
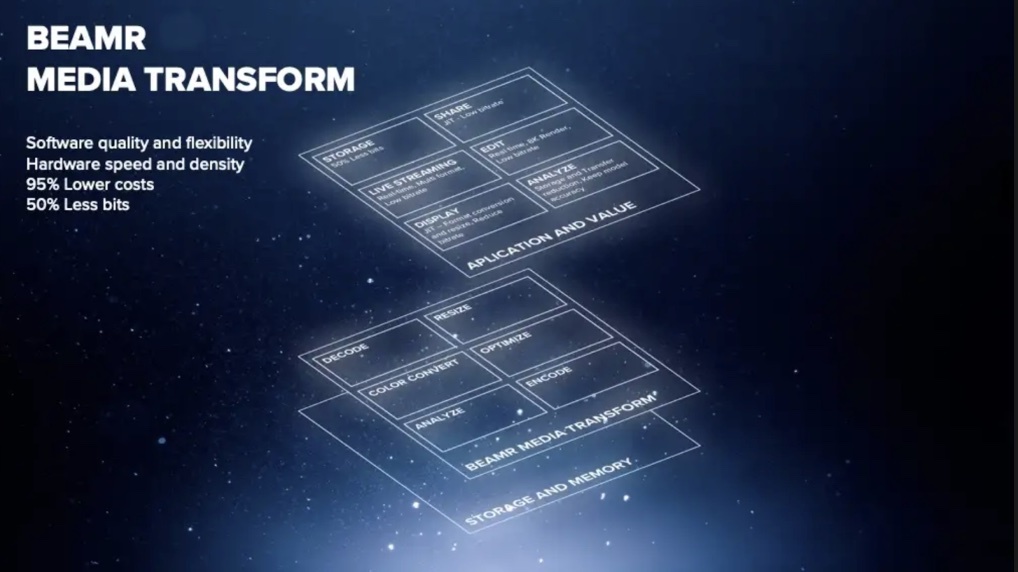
Is the Future of Video Processing Destined for GPU?
My Journey Through the Evolution of Video Processing: From Low-Quality Streaming to HD and 4K Becoming a Commodity, and Now the AI-Powered…