
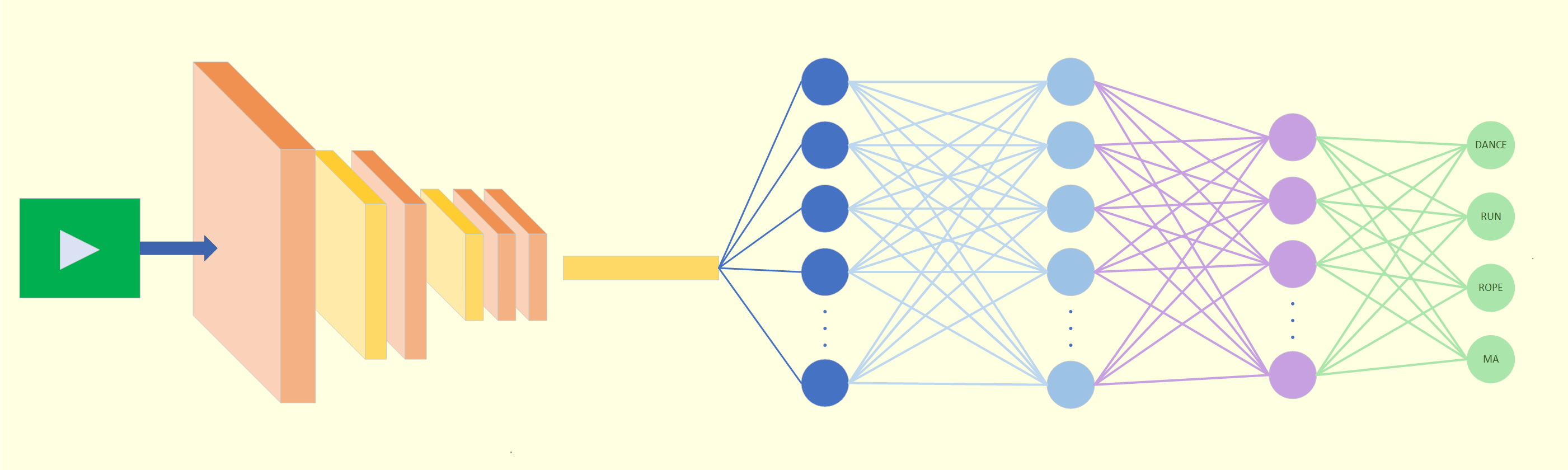
Introduction
Machine learning for Video is an expanding field, garnering vast interest, with generative AI for video picking up speed. However there are significant pain points for these technologies such as storage and bandwidth bottlenecks when dealing with video content, as well as training and inferencing speeds.
In the following case study, we show that training an AI network for action recognition using video files compressed and optimized through Beamr Content-Adaptive Bitrate technology (CABR), produces results that are as good as training the network with the original, larger files. The ability to use significantly smaller video files can accelerate machine learning (ML) training and inferencing.
Motivation
Beamr’s CABR enables significantly decreasing video file size without changing the video resolution, compression or file format or compromising perceptual quality. It is therefore a great candidate for resolving file size issues and bandwidth bottlenecks in the context of ML for video.
In a previous case study we looked at the task of people detection in video using pre-trained models. In this case study we cover the more challenging task of training a neural network for action recognition in video, comparing the outcome when using source vs optimized files.
We will start by describing the problem we targeted, and then provide the classifier architecture used. We will continue with details on the data sets used and their optimization results, followed by the experiment results, concluding with directions for future work.
Action recognition task
When setting the scope for this case study it was essential to us to define a test case that makes full use of the fact that the content is video, as opposed to image. Therefore we selected a task which requires the temporal element of video to perform the classification – action recognition. In viewing individual frames it is not possible to differentiate between frames captured during walking and running, or between someone jumping or dancing. For this a sequence of frames is required, which is why this was our task of choice.
Target data set
For the fine tuning step we collected a set of 160 user-generated content free to use video clips, downloaded from the Pexels and Envato stock-video websites. The videos were downloaded in 720p resolution, using the website default settings. We selected videos that belong to one of the following four action classes or categories: running, martial arts, dancing and rope jumping.

In order to use these in the selected architecture, they needed to be cropped to a square input. This was done by manually marking “ROI” in each clip, and performing the crop using OpenCV and corresponding OpenH264 encoding with default configuration and settings.
We first performed optimization of the original clip set, using the Beamr cloud optimization SaaS, obtaining an average reduction of 24%. This is beneficial when storing the test set for future use and possibly performing other manipulations on it. However, for our test we wanted to compress the set of cropped videos that were actually used for the training process. Applying the same optimization to these files, created by openCV, yielded a whopping 67% savings or average reduction.
Architecture
We selected an encoder-decoder architecture, which is commonly used for classification of video or other time series inputs. For the encoder we used ResNet-152 pre-trained with ImageNet, followed by 3 fully connected layers with sizes of 1024, 768 and 512. For the decoder we used an LSTM decoder followed by 2 fully connected layers consisting of 512 and 256 neurons.
Pre-training
We performed initial training of the network using the UCF-101 dataset which consists of 13,320 video clips, at a resolution of 240p, classified into 101 possible action classes. The data was split so that 85% of the files were used for the training and 15% for validation.
These videos were resized to 224 x 224 prior to feeding into the classifier. The training was done using a batch size of 24, and 35 epochs were performed. For the error function we used cross-entropy loss which is a popular choice for classifier training. The Adaptive Moment Estimation, or Adam, optimizer with a learning rate of 1e-3 was selected for the training process as it solves the problems of local minima, overshoot or oscillation caused by the fixed values of the learning rates during the updating of network parameters. This setup yielded a result of 83% accuracy on the validation set.
Training
We performed fine tuning of the pre-trained network described above, to learn the target data set..
The training was performed on 2.05 GB of cropped videos, and on 0.67 GB of cropped & optimized videos, with 76% of the files used for training and 24% for validation.
Due to the higher resolution of the input in the target data set the fine tuning training was done using a batch size of only 4. 30 epochs were performed, though we generally achieved convergence already at 9-10 epochs. Again we used cross-entropy loss and Adam optimizer with a learning rate of 1e-3.
Due to the relatively small sample size used here, a difference in one or two classifications can alter results, so we repeated the training process 10 times for each case in order to obtain confidence in the results. The obtained accuracy results for the 10 testing rounds on each of the non-optimized and optimized video sets are presented in the following table.
| Minimum Accuracy | Average Accuracy | Maximum Accuracy | |
| Non-Optimized Videos | 56% | 65% | 69% |
| Optimized Videos | 64% | 67% | 75% |
To further verify the results we collected a set of 48 additional clips, and tested these independently on each of the trained classifiers. Below we provide the full cross matrix of maximum and mean accuracy obtained for the various cases.
| Tested on Non-Optimized | Tested on Optimized | |
| Trained on Non-Optimized | 65%, 53% | 62%, 50% |
| Trained on Optimized | 62%, 50% | 65%, 50% |
Summary & Future work
the results shared above confirm that training a neural network with significantly smaller video files, optimized by Beamr’s CABR, has no negative impact on the training process. In this experiment we even saw a slight benefit resulting from training using optimized files. However, it is unclear if this is a significant conclusion, and we intend to investigate this further. We also see that the cross testing/training has similar results in the different cases.
This test was an initial, rather small scale experiment. We are planning to expand this to larger scale testing, including distributed training setups in the cloud using GPU clusters, where we expect to see further benefits from the reduced sizes of the files used.
This research is part of our ongoing quest to accelerate adoption, and increase accessibility of machine learning and deep learning video as well as video analysis solutions.


