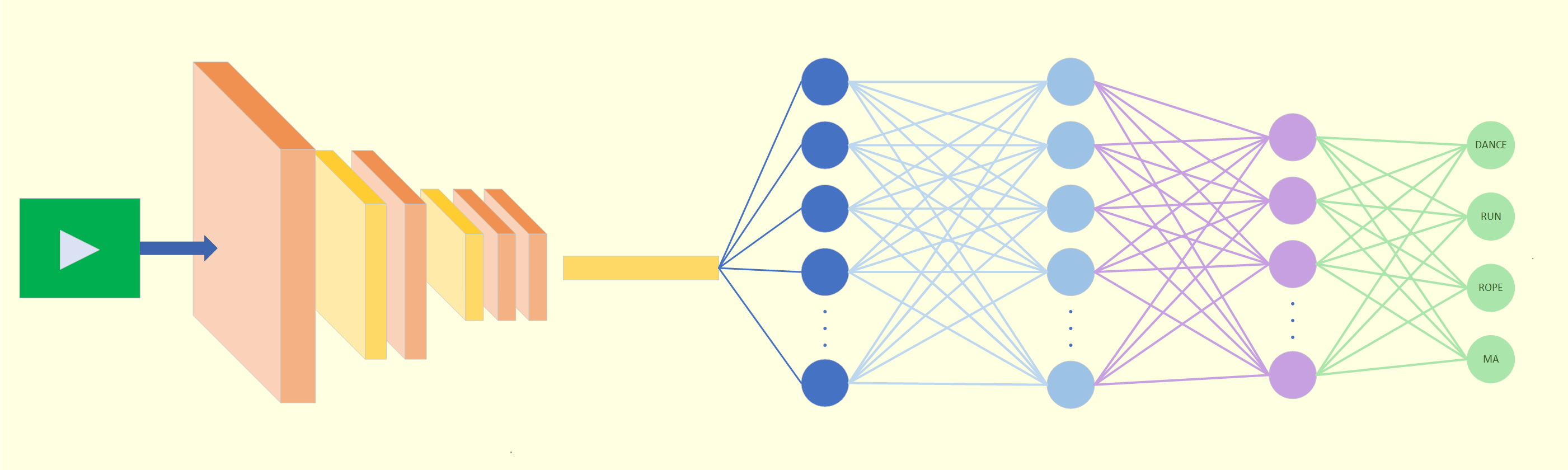
By video size but not perceptual quality, Beamr’s Content Adaptive Bit Rate optimized encoding can make video used for vision AI easier to handle thus reducing workflow complexity
Written by: Tamar Shoham, Timofei Gladyshev
Motivation
Machine learning (ML) for video processing is a field which is expanding at a fast pace and presents significant untapped potential. Video is an incredibly rich sensor and has large storage and bandwidth requirements, making vision AI a high-value problem to solve and incredibly suited for AI and ML.
Beamr’s Content Adaptive Bit rate solution (CABR) is a solution that can significantly decrease video file size without changing the video resolution, compression or file format or compromising perceptual quality. It therefore interested us to examine how the Beamr CABR solution can be used to assist in cutting down the sizes of video used in the context of ML.
In this case study, we focus on the relatively simple task of people detection in video. We made use of the NVIDIA DeepStream SDK, a complete streaming analytics toolkit based on GStreamer for AI-based multi-sensor processing, video, audio and image understanding. Using this SDK is a natural choice for Beamr as an NVIDIA Metropolis partner.
In the following we describe the test setup, the data set used, test performed and obtained results. Then we will present some conclusions and directions for future work.
Test Setup
In this case study, we limited ourselves to comparing detection results on source and reduced-size files by using pre-trained models, making it possible to use unlabeled data.
We collected a set of 19 User-Generated Content, or UGC, video clips, captured on a few different iPhone models. To these we added some clips downloaded from the Pexels free stock videos website. All test clips are in the mp4 or v file format, containing AVC/H.264 encoded video, with resolutions ranging from 480p to full HD and 4K and durations ranging from 10 seconds to 1 minute. Further details on the test files can be found in Annex A.
These 14 source files were then optimized using Beamr’s storage optimization solution to obtain files that were reduced in size by 9 – 73%, with an average reduction of 40%. As mentioned above, this optimization results in output files which retain the same coding and file formats and the same resolution and perceptual quality. The goal of this case study is to show that these reduced-size, optimized files also provide aligned ML results.
For this test, we used the NVIDIA DeepStream SDK [5] with the PeopleNet-ResNet34 detector. Once again, we calculated the mAP among the detections on the pairs of source and optimized files for an IoU threshold of 0.5.
Results
We found that for files with predictions that align with actual people, the mAP is very high, showing that true detection results are indeed unaffected by replacing the source file with the smaller, easier-to-transfer, optimized file.
An example showing how well they align is provided in Figure 1. This test clip resulted in a mAP[0.5] value of 0.98.


As the PeopleNet-ResNet34 model was developed specifically for people detection, it has quite stable results, and overall showed high mAP values with a median mAP value of 0.94.
When testing some other models we did notice that in cases where the detections were unstable, the source and optimized files sometimes created different false positives. It is important to note that because we did not have labeled data, or a ground truth, when such detection errors occur out of sync, they have a double impact on the mAP value calculated between the detections on the source and the detections on the optimized file. This results in poorer results than the mAP values expected when calculating for detections vs. the labeled data.
We also noticed cases where there is a detection flicker, with the person being detected only in some of the frames where they appear. This flicker is not always synchronized between the source and optimized clips, resulting once again in an ‘accumulated’ or double error in the mAP calculated among them. An example of this is shown in Figure, for a clip with a mAP[0,5] value of 0.92.




Summary
The experiments described above show that CABR can be applied to videos that undergo ML tasks such as object detection. We showed that when detections are stable, almost identical results will be obtained for the source and optimized clips. The advantages of reducing storage size and transmission bandwidth by using the optimized files make this possibility particularly attractive.
Another possible use for CABR in the context of ML stems from the finding that for unstable detection results, CABR may have some impact on false positives or mis-detects. In this context, it would be interesting to view it as a possible permutation on labeled data to increase training set size. In future work, we will investigate the further potential benefits obtained when CABR is incorporated at the training stage and expand the experiments to include more model types and ML tasks.
This research is all part of our ongoing quest to accelerate adoption and increase the accessibility of video ML/DL and video analysis solutions.
Annex A – test files
Below are details on the test files used in the above experiments. All the files, and detection results are available here
| # | Filename | Source | Bitrate | Dims WxH | FPS | Duration [sec] | saved by CABR |
| 1 | IMG_0226 | iPhone 3GS | 3.61 M | 640×480 | 15 | 36.33 | 35% |
| 2 | IMG_0236 | iPhone 3GS | 3.56 M | 640×480 | 30 | 50.45 | 20% |
| 3 | IMG_0749 | iPhone 5 | 17.0 M | 1920×1080 | 29.9 | 11.23 | 34% |
| 4 | IMG_3316 | iPhone 4S | 21.9 M | 1920×1080 | 29.9 | 9.35 | 26% |
| 5 | IMG_5288 | iPhone SE | 14.9 M | 1920×1080 | 29.9 | 43.40 | 29% |
| 6 | IMG_5713 | iPhone 5c | 16.3 M | 1080×1920 | 29.9 | 48.88 | 73% |
| 7 | IMG_7314 | iPhone 7 | 15.5 M | 1920×1080 | 29.9 | 54.53 | 50% |
| 8 | IMG_7324 | iPhone 7 | 15.8 M | 1920×1080 | 29.9 | 16.43 | 39% |
| 9 | IMG_7369 | iPhone 6 | 17.9 M | 1080×1920 | 29.9 | 10.23 | 30% |
| 10 | pexels_musicians | pexels | 10.7 M | 1920×1080 | 24 | 60.0 | 44% |
| 11 | pexels_video_1080p | pexels | 4.4 M | 1920×1080 | 25 | 12.56 | 63% |
| 12 | pexels_video_2160p | pexels | 12.2 M | 3840×2160 | 25 | 15.24 | 9% |
| 13 | pexels_video_2160p_2 | pexels | 15.2 M | 3840×2160 | 25 | 15.84 | 54% |
| 14 | pexels_video_of_people_walking_1080p | pexels | 3.5 M | 1920×1080 | 23.9 | 19.19 | 58% |
Table A1: Test files used, with the per file savings