4K TV CABR Live NVIDIA VISTA2 Min Read Tamar ShohamonJuly 1, 2026 The Higher-Resolution Streaming Your Viewers Expect on the Pipeline You Already Have The Beamr stack for live sports broadcast powered by NVIDIA: 4K and 1080p outputs from lower-resolution sources – validated on your own…
Broadcast CABR Video Quality VISTA4 Min Read Tamar ShohamonApril 10, 2026 Deliver Video Transformation With Confidence Beamr VISTA closes the gap between fast but limited objective metrics and reliable but unscalable subjective testing In broadcasting, encoding…
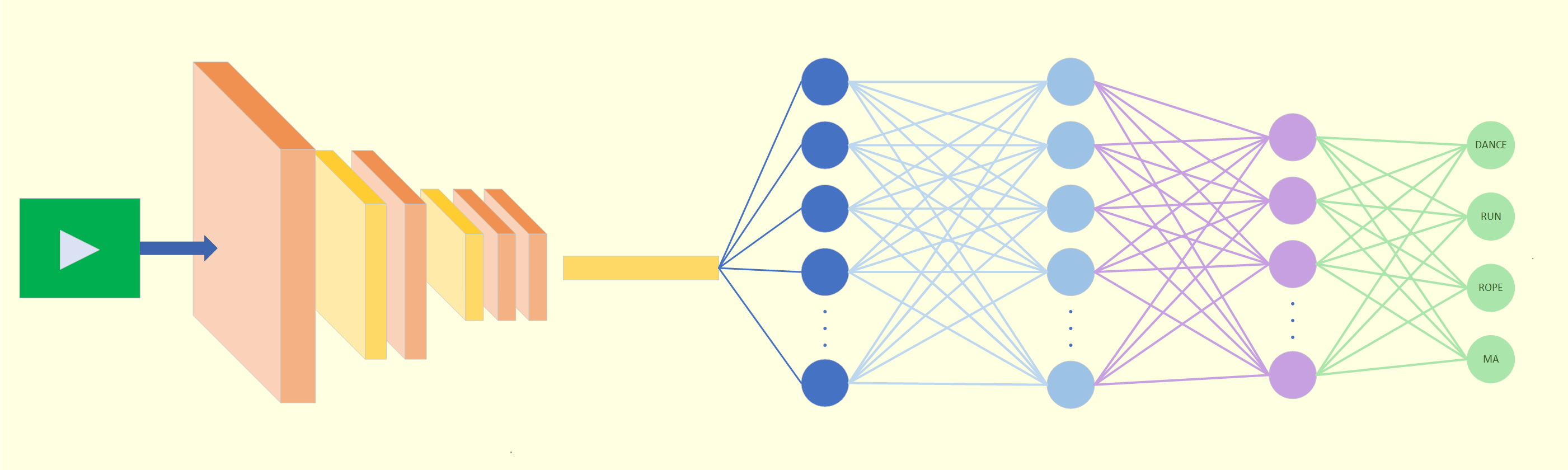
AI Autonomous Vehicles CABR GPU Machine Learning7 Min Read Tamar ShohamonJune 10, 2025 How Content-Adaptive Video Compression Tackles Autonomous Vehicle Data Explosion By Ronen Nissim and Tamar Shoham Overview The explosion of video data in autonomous vehicles (AVs) systems presents a critical challenge to…
AOM AV1 AVC H.264 H.265 HEVC Video Encoding Video Trends3 Min Read Tamar ShohamonDecember 26, 2024 The Video Codec Race to 2025: How AV1 is Driving New Possibilities With numerous advantages, AV1 is now supported on about 60% of devices and all major web browsers. To accelerate its adoption – Beamr…
4K TV AOM AV1 CABR Content-Adaptive IBC Live NVIDIA3 Min Read Tamar ShohamonSeptember 10, 2024 Live 4Kp60 Optimized Encoding with Beamr CABR and NVIDIA Holoscan for Media This year at IBC 2024 in Amsterdam, we are excited to demonstrate Live 4K p60 optimized streaming with our Content-Adaptive Bitrate (CABR)…
AI AOM AV1 Codec Modernization Machine Learning2 Min Read Tamar ShohamonAugust 11, 2024 Using Beamr Cloud Optimized AV1 Encodes for Machine Learning Tasks Now available: Hardware accelerated, unsupervised, codec modernization to AV1 for increased efficiency video AI workflows AV1, the new kid on…
AOM AV1 Beamr Cloud CABR GPU NVENC NVIDIA Oracle Cloud Infrastructure (OCI)2 Min Read Tamar ShohamonJune 23, 2024 Beamr Now Offering Oracle Cloud Infrastructure Customers 30% Faster Video Optimization Beamr’s Content Adaptive Bit Rate solution enables significantly decreasing video file size or bitrates without changing the video…
AI CABR Machine Learning5 Min Read Tamar ShohamonMarch 18, 2024 Beamr Tech boosts Video Machine Learning: Taking a look at training Introduction Machine learning for Video is an expanding field, garnering vast interest, with generative AI for video picking up speed. However…
AI CABR Machine Learning4 Min Read Tamar ShohamonDecember 8, 2023 Beamr CABR Poised to Boost Vision AI By reducing video size but not perceptual quality, Beamr’s Content Adaptive Bit Rate optimized encoding can make video used for vision AI…
AVC Beamr 4 Beamr 5 CABR Codec Modernization Encoder Applications H.264 H.265 HDR HEVC/VP9 NVENC NVIDIA x264 x2654 Min Read Tamar ShohamonJune 14, 2023 Automatically Upgrade Your Video Content to a New and Improved Codec Easy & Safe Codec Modernization with Beamr using Nvidia GPUs Following a decade where AVC/H.264 was the clear ruler of the video…