


Using Beamr Cloud Optimized AV1 Encodes for Machine Learning Tasks
Now available: Hardware accelerated, unsupervised, codec modernization to AV1 for increased efficiency video AI workflows AV1, the new kid on…

Beamr Now Offering Oracle Cloud Infrastructure Customers 30% Faster Video Optimization
Beamr’s Content Adaptive Bit Rate solution enables significantly decreasing video file size or bitrates without changing the video…

Real-time Video Optimization with Beamr CABR and NVIDIA Holoscan for Media
This year at the NAB Show 2024 in Las Vegas, we are excited to demonstrate our Content-Adaptive Bitrate (CABR) technology on the NVIDIA…
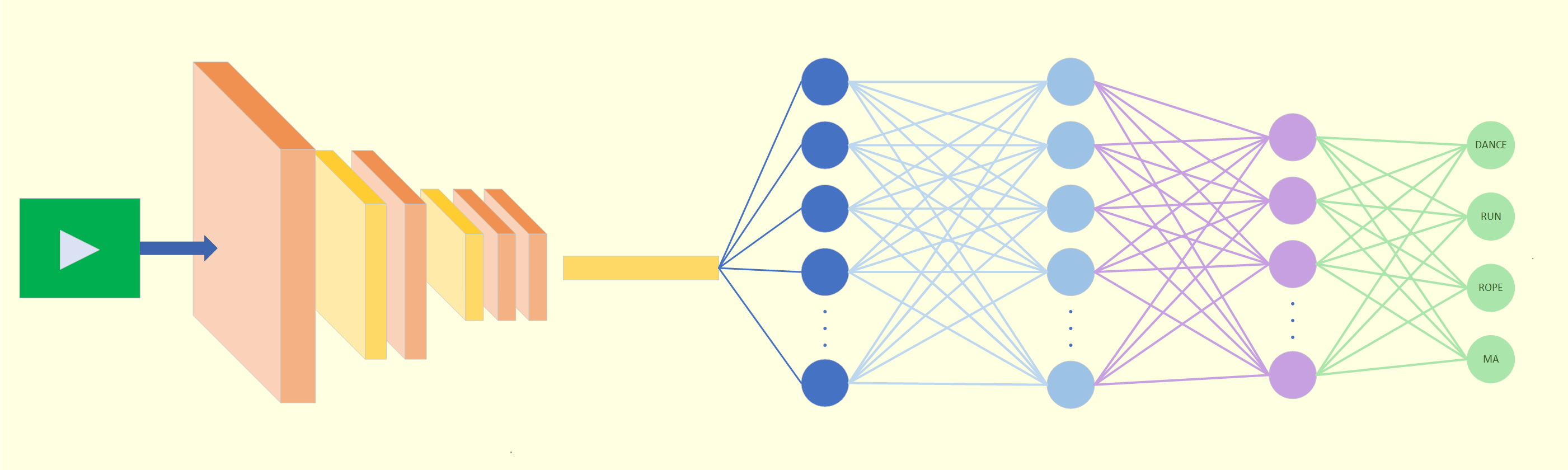
Beamr Tech boosts Video Machine Learning: Taking a look at training
Introduction Machine learning for Video is an expanding field, garnering vast interest, with generative AI for video picking up speed. However…
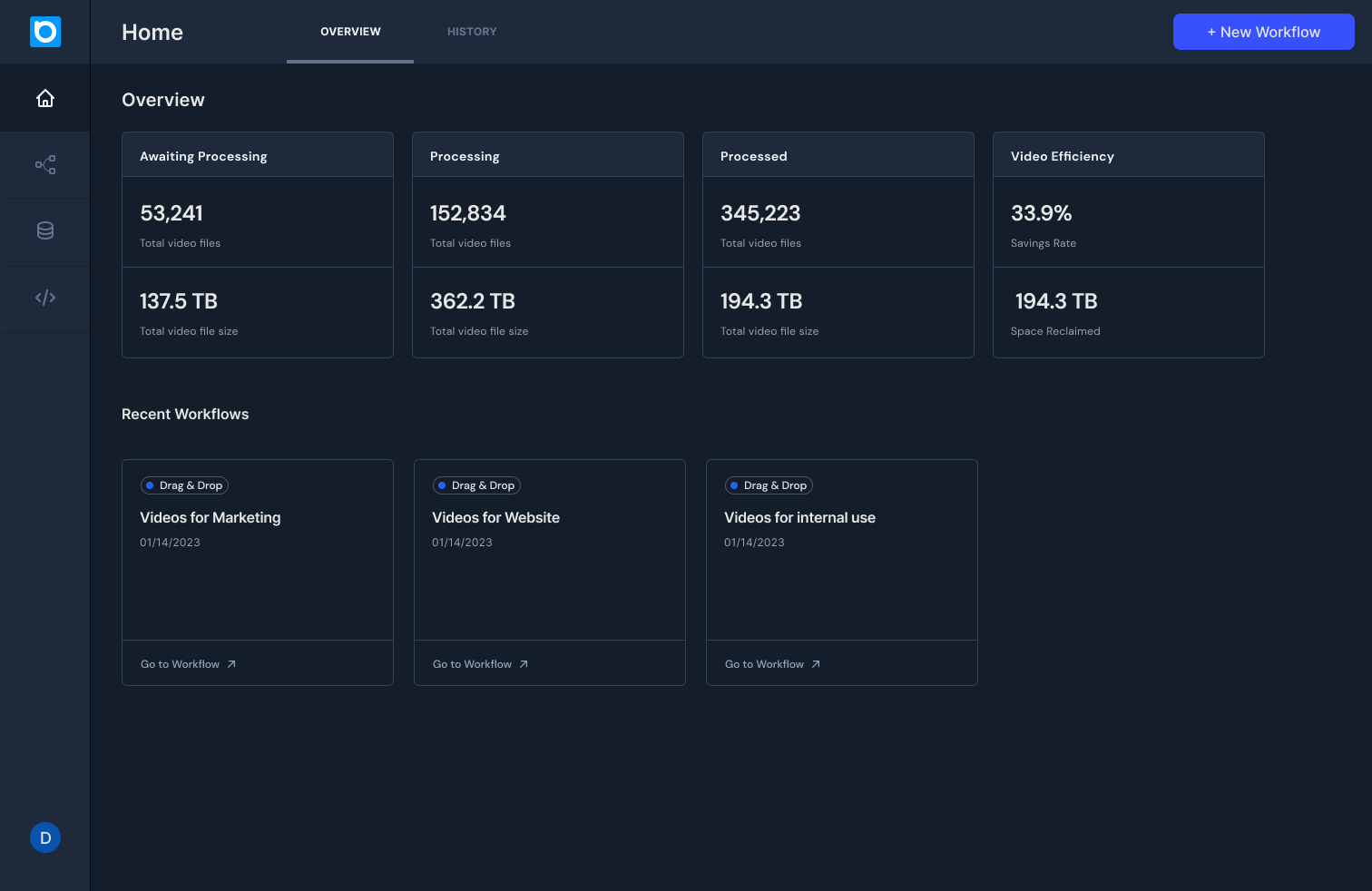
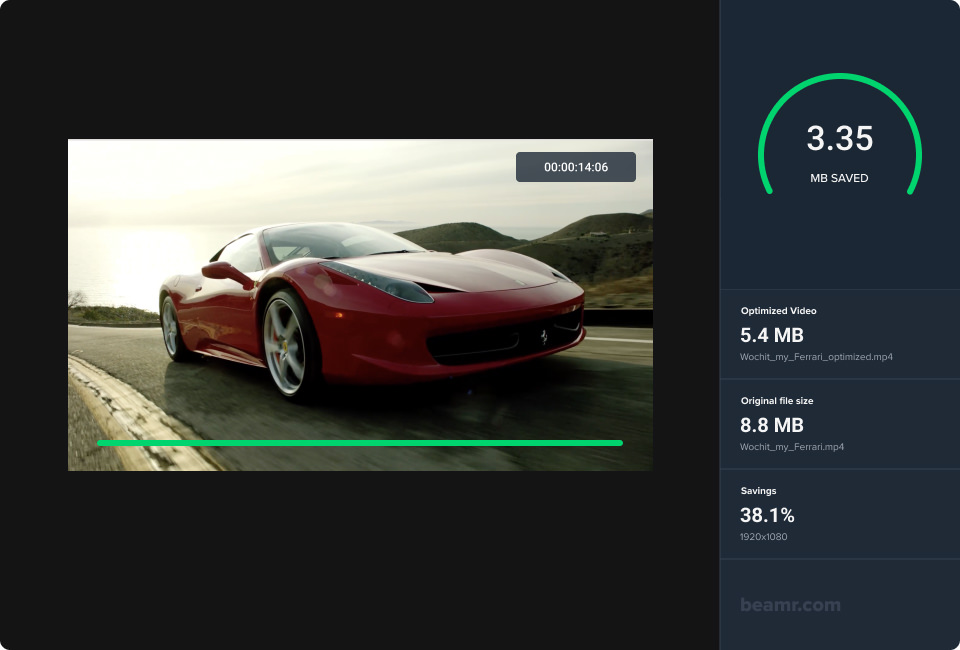
Beamr Cloud is live!
High Quality, High Scale, Low Cost video processing – Beamr Cloud is bringing technology that used to be exclusive to tech giants like…

Beamr CABR Poised to Boost Vision AI
By reducing video size but not perceptual quality, Beamr’s Content Adaptive Bit Rate optimized encoding can make video used for vision AI…

Automatically Upgrade Your Video Content to a New and Improved Codec
Easy & Safe Codec Modernization with Beamr using Nvidia GPUs Following a decade where AVC/H.264 was the clear ruler of the video…
Beamr Helps Businesses Keep Up With Generative AI Video Content
The proliferation of AI-generated visual content is creating a new market for media optimization services, with companies like Beamr well…

Beamr teams with NVIDIA to accelerate Beamr technology on NVIDIA GPUs
2023 is a very exciting year for Beamr. In February Beamr became a public company on NASDAQ:BMR on the premise of making our video…

Beamr Named Seagate Lyve Innovator of the Year 2021
We are thrilled to share with you that Beamr has won the Seagate Lyve Innovator of the Year competition!