AI Autonomous Vehicles CABR Content-Adaptive Machine Learning5 Min Read Ethan FenakelonJanuary 5, 2026 Deep Dive: Managing the Petabyte-Scale AV Video Data Bottlenecks ML-Safe Testing Series, Part 3: Optimized video data processing for AV – 20%-50% file size reduction with remarkable detection,…
AI Autonomous Vehicles CABR Content-Adaptive Machine Learning3 Min Read Ronen NissimonDecember 18, 2025 ML-Safe AV Video Data Processing Achieves Up to 50% Storage Reduction ML-Safe Testing Series, Part 2: Benchmark testing shows how AV developers can achieve greater savings across storage, networking and compute…
4K TV AOM AV1 CABR Content-Adaptive IBC Live NVIDIA3 Min Read Tamar ShohamonSeptember 10, 2024 Live 4Kp60 Optimized Encoding with Beamr CABR and NVIDIA Holoscan for Media This year at IBC 2024 in Amsterdam, we are excited to demonstrate Live 4K p60 optimized streaming with our Content-Adaptive Bitrate (CABR)…
CABR Cloud Gaming Codec Performance Content-Adaptive Intel Gen 11 Graphics Intel Media SDK7 Min Read Dror GillonNovember 19, 2019 How To Cut Cloud Gaming Bitrates In Half So That Twice As Many Users Can Play TL;DR: Beamr CABR operating with the Intel Media SDK hardware encoder powered by Intel GPUs is the perfect video encoding engine for cloud…
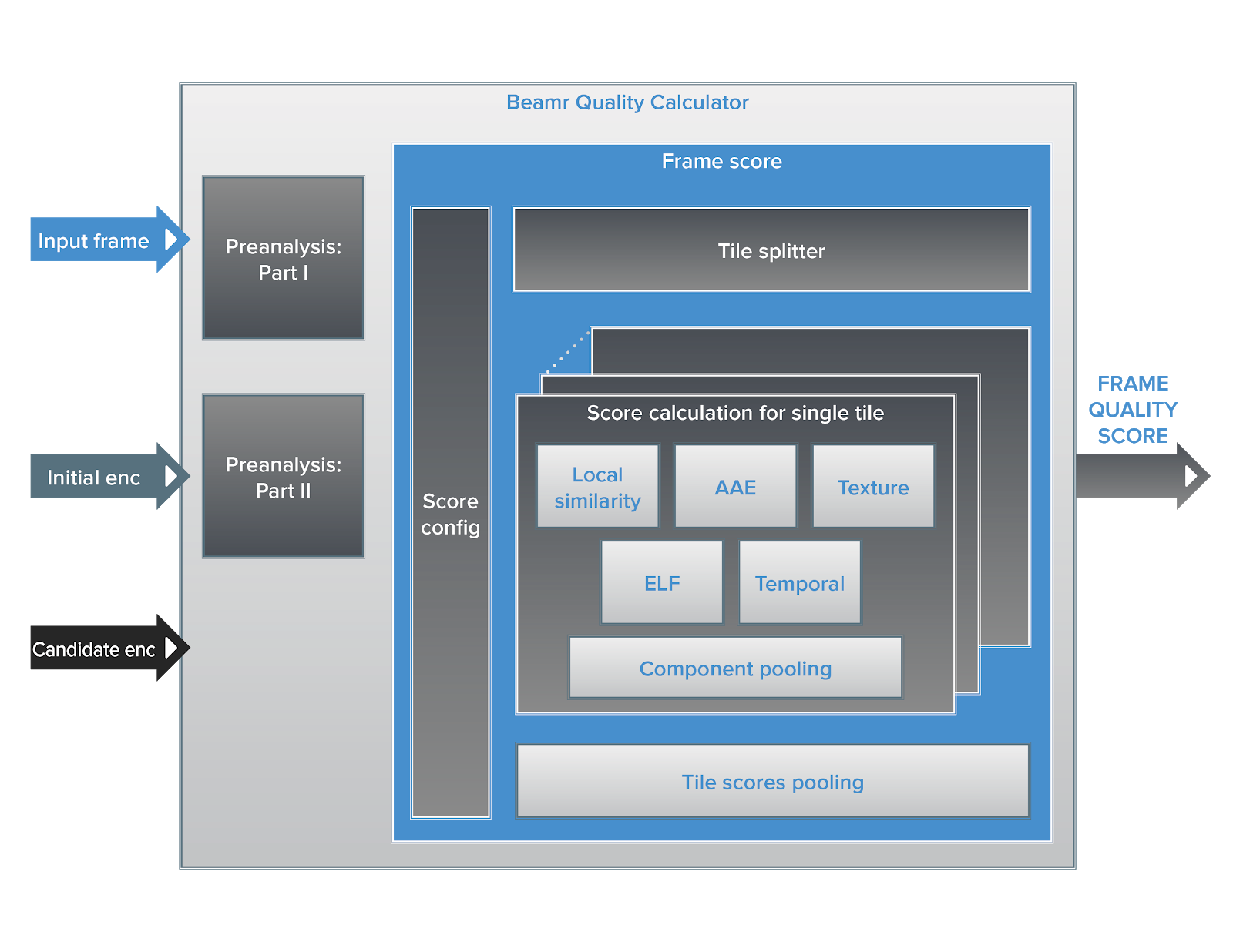
CABR Content-Adaptive quality measure8 Min Read Tamar ShohamonSeptember 11, 2019 The Patented Visual Quality Measure that was Designed to Drive Higher Compression Efficiency At the heart of Beamr’s closed-loop content-adaptive encoding solution (CABR) is a patented quality measure. This measure compares the…
Beamr 5 CABR Content-Adaptive9 Min Read Tamar ShohamonSeptember 11, 2019 A Deep Dive into CABR, Beamr’s Content-Adaptive Rate Control Going Inside Beamr’s Frame-Level Content-Adaptive Rate Control for Video Coding When it comes to video, the tradeoff between quality and…
4K TV Beamr 5 Content-Adaptive Encoder Applications H.265 HDR HEVC IBC Mobile Video OTT Reduce Bitrate1 Min Read Dror GillonOctober 31, 2017 How to deal with the tension on the mobile network – part 2 (VIDEO Interview) In late July, I reported on the “news” that Verizon was throttling video traffic for some users. As usual, the facts around this…
Content-Adaptive H.265 HEVC WWDC20171 Min Read Dror GillonJune 14, 2017 We Celebrate with Cake! At Beamr, when we celebrate, we do it with cake! Today’s very special, and oh so yummy cake celebration, was a recognition of the…
Content-Adaptive H.264 H.265 HEVC Reduce Bitrate8 Min Read Dror GillonMarch 7, 2017 How the Magic of Beamr Beats SSIM and PSNR Every video encoding professional faces the dilemma of how best to detect artifacts and measure video quality. If you have the luxury of…
Content-Adaptive Uncategorized3 Min Read Dror GillonApril 28, 2016 Content-Adaptive Optimization is Bringing Next Level Performance to OTT and Broadcast Encoding Workflows As the digital landscape continues to grow, it’s no surprise that the demand for a high-quality and reliable streaming video experience on…