

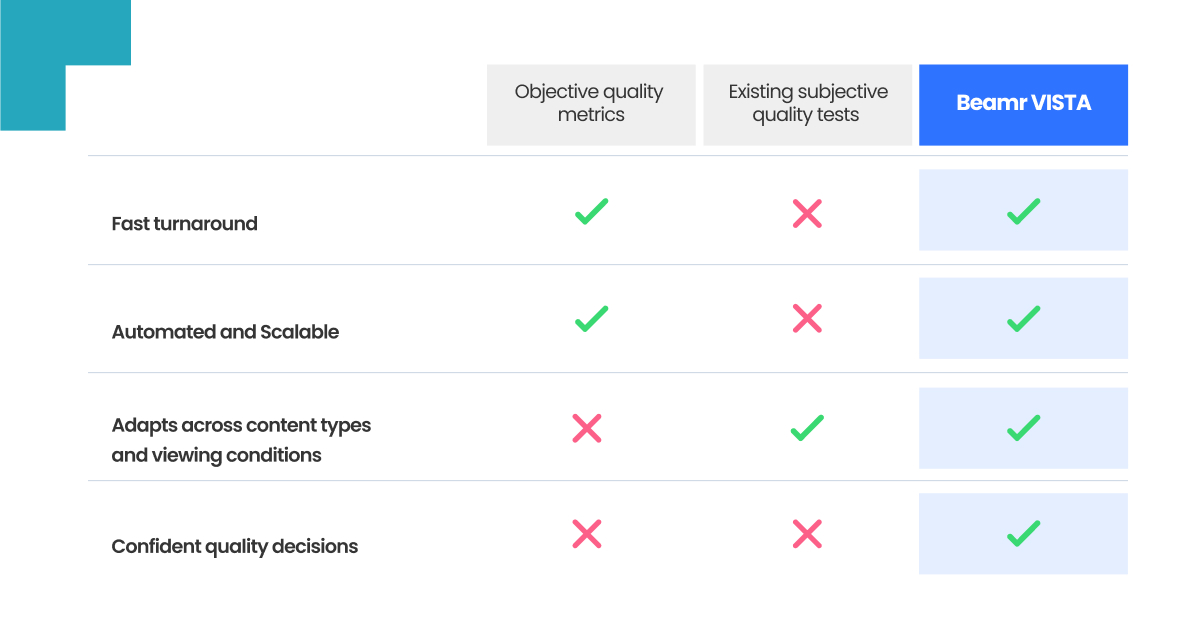
Beamr VISTA closes the gap between fast but limited objective metrics and reliable but unscalable subjective testing
In broadcasting, encoding development and AI generated media, every video transformation raises the same challenging question: will viewers notice a difference?
Teams shipping quality-sensitive changes can’t tolerate any degradation to the visual appearance of content. Rollbacks are expensive, and a bad quality decision means emergency fixes, uncontrollable expenses and lost trust for the viewers. This has always been true, but in the era of 4K and 8K resolutions, HDR screens and AI-driven video it becomes even more essential.
▶️ Run your first test, visit beamr.com/vista
The tools available don’t match the decisions being made
The debate on how to reliably and efficiently measure quality is yet to be settled. The two main approaches are subjective quality measurement, based on real human viewers’ feedback, and objective, based on calculated metric evaluation.
Subjective quality testing is the “gold standard”, providing the most reliable assessment across different content types, codecs, and applications. However, it remains too often a time consuming and an expensive process – requiring specified controlled viewing conditions: calibrated monitors, defined room illumination, specific background chromaticity.
The result is that in many cases evaluation of video quality is done using objective measures, which may be poorly correlated with actual subjective results. Metrics such as PSNR, SSIM, VMAF are fast, low-cost, and scalable, but they measure mathematical distortion, not human perception. They can be easily “fooled” and often overlook perceptual quality loss. Generally, they do not adapt well across various content types and video processing workflows.
Objective measures usually won’t be sufficient when testing in multifaceted scenarios, beyond a very specific codec or context. Video engineers know this gap firsthand: a metric returns ‘pass’ while the image visibly fails the eye test. This is evident across broad use cases, from Hollywood movies and high-quality videos to user-generated content and gaming.
This is not just a practical limitation, the insufficient correlation of objective metrics with the “ground truth” of actual human perception is a built-in property of these methods. They should not be used as the sole indicator for video quality, and definitely not across various content types and scenarios.
Validated answers without the guesswork
To bridge the gap between objective metrics limitations and subjective testing complexity, Beamr developed VISTA (Visual Subjective Testing Application) — a platform for subjective video quality testing at scale. VISTA was built using a methodology designed for production decisions rather than lab conditions, delivering the human input that objective metrics cannot provide. It was developed initially to tune and validateBeamr’s own content-adaptive technology, and is now available to the video industry.
VISTA answers the two questions that drive most quality validation workflows:
- Does this transformation preserve quality?
Relevant for compression, pipeline changes, cost-reduction initiatives, AI model updates. The goal is confirming that no visible degradation has been introduced before changes go live. - Does this transformation look better?
Relevant for upscaling, quality enhancement, encoding development, AI-generated content evaluation. The goal is confirming that a visible improvement is real, not just a metric improvement.

How VISTA works
VISTA viewing sessions are easy to use, allowing the user to focus purely on the video quality assessment, as they watch a stream of side-by side comparisons. VISTA uses a Double-stimulus forced choice methodology. Viewers watch two clips side by side, and must choose which one looks worse. There is no neutral option. This removes response bias, and requires active engagement. This method has been proven¹ to be the most reliable to use in subjective quality assessment and also the most sensitive to identify even small variations between the two files, which is a key consideration.
To verify the viewers reliability, each session includes Viewer verification pairs – clips with a visible but non-obvious degradation on one side. Only viewers who correctly identify these control pairs are included in the analysis, filtering out participants who are guessing or disengaged. Sometimes tests also include pairs showing the same clip on both sides, in order to gather information regarding the statistical significance of the obtained results.
Tests can run through a validated viewer pool through crowdsourcing platforms, such as Amazon Mechanical Turk, for fast turnaround; or with an internal viewing team, for premium or sensitive content. The pricing is usage-based.
Results are delivered as a structured report: which version viewers preferred, by what margin, and with what level of statistical confidence. A clear answer the team can act on.

VISTA brings reliable, scalable, and data-driven feedback. The feedback reflects real-world viewing behavior, and because the platform scales testing group size to match the required confidence level, results carry the statistical backing to support production decisions.
The data VISTA generates has value beyond individual test results. Large-scale, human-validated comparative data is increasingly what AI-driven video workflows require — to train models, verify outputs, and close the loop between algorithmic optimization and perceptual reality.
▶️ Run your first test, visit beamr.com/vista
Built to solve Beamr’s own challenge
Beamr built VISTA to solve our specific need: validating the perceptual quality decisions we made while developing our patented Content-Adaptive Bitrate technology (CABR).
Lab-based subjective testing was too slow. Objective metrics weren’t reliable enough. The team needed real human signals at production speed and scale – so we built the tool for that. The methodology, viewer verification mechanisms, and statistical framework were developed and refined against real engineering problems. We performed over 80 test sessions, with a total of 976 target pair viewings by what we consider valid users and found that the CABR encodes were perceptually identical with statistical confidence exceeding 95%.
1 Rafał K. Mantiuk, Anna Tomaszewska, and Radosław Mantiuk. 2012. Comparison of Four Subjective Methods for Image Quality Assessment. Comput. Graph. Forum 31, 8 (December 2012), 2478–2491. https://doi.org/10.1111/j.1467-8659.2012.03188.x

