AI Autonomous Vehicles CABR GPU Machine Learning NVENC NVIDIA3 Min Read Dani MegrelishvilionAugust 13, 2025 Beamr is Pushing the Boundaries of AV Data Efficiency, Accelerated by NVIDIA Designed to protect visual fidelity, Beamr’s solution helps address the infrastructure challenges associated with autonomous vehicle…
AI Autonomous Vehicles CABR GPU Machine Learning7 Min Read Tamar ShohamonJune 10, 2025 How Content-Adaptive Video Compression Tackles Autonomous Vehicle Data Explosion By Ronen Nissim and Tamar Shoham Overview The explosion of video data in autonomous vehicles (AVs) systems presents a critical challenge to…
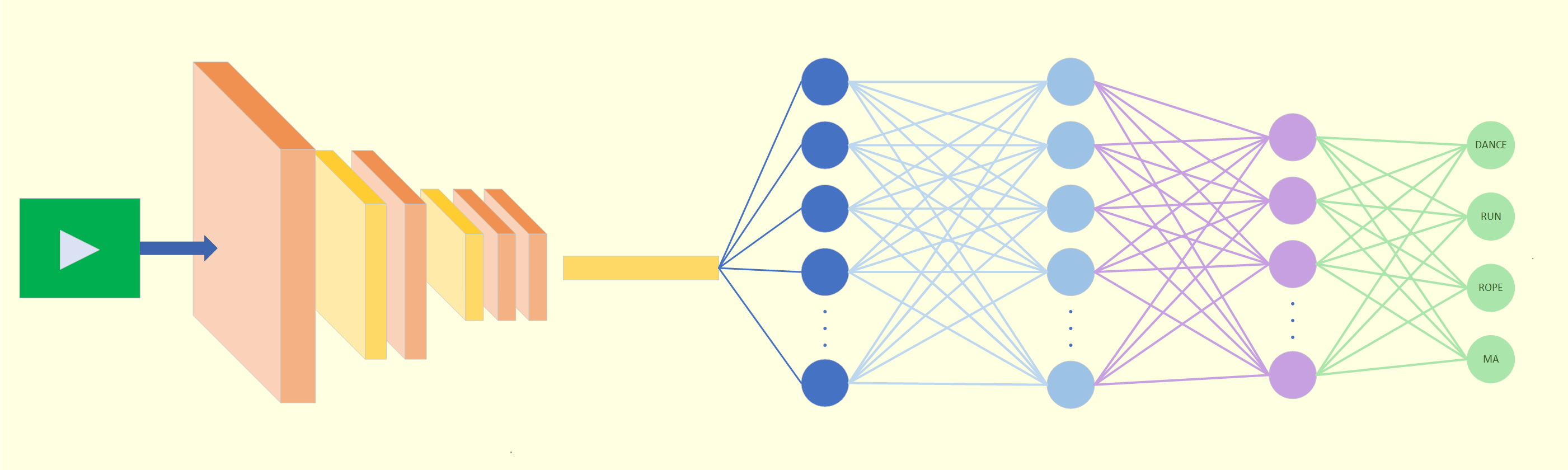
AI CABR Machine Learning5 Min Read Tamar ShohamonMarch 18, 2024 Beamr Tech boosts Video Machine Learning: Taking a look at training Introduction Machine learning for Video is an expanding field, garnering vast interest, with generative AI for video picking up speed. However…
AI CABR Machine Learning4 Min Read Tamar ShohamonDecember 8, 2023 Beamr CABR Poised to Boost Vision AI By reducing video size but not perceptual quality, Beamr’s Content Adaptive Bit Rate optimized encoding can make video used for vision AI…