

AV video data compressed with Beamr’s patented Content-Adaptive Bitrate (CABR) technology achieved 35.2% file size reduction, and lowered depth error on safety-critical vulnerable road users (VRUs), like pedestrians and motorcyclists, by 30.7%
Managing the petabyte-scale machine vision real-time and synthetic video data requires compression. At the same time, applying compression to machine vision data pipelines requires confidence that downstream model accuracy is preserved. As a step forward in developing ML-safe video data processing, this study demonstrates that treating compression as a training strategy allows to scale efficiently while preserving the perception accuracy AI systems depend on. This study focuses on depth estimation – the perception task that produces a depth map, and is among the most sensitive to any change in input.

Compression as Augmentation
Commonly used codecs are inherently lossy. While often visually lossless to human observers, they can distort spatial geometry, specifically for high-frequency information that machine learning models may rely on. In particular, dense, pixel-specific tasks in the AI perception stack – such as monocular depth estimation – are notoriously sensitive to any video transformation, including compression artifacts.
We propose a new approach: video data compression should be utilized as data augmentation during model training to effectively improve the model learning and robustness. Just as models are trained with synthetic blur or noise to handle adverse weather, injecting compression artifacts into the training pipeline forces the network to learn geometric representations that are natively robust to telematics (i.e. transmission of computerized information) challenges, among which video compression is prominent.
Since lossy compression inherently discards fine spatial details regardless of the codec used, processing these compressed inputs degrades the model’s depth predictions compared to its clean-input baseline. To overcome this, we performed targeted model fine-tuning using the compressed videos, and achieved significant reduction in the validation errors using this approach.
Experiment Setup
In our prior testing, depth models showed measurable sensitivity to compressed input – even when the compression introduced no visible change to the video. To validate the “compression as augmentation” approach, we examined the impact of video compression on Depth Anything V2 (Base), a state-of-the-art monocular relative depth estimation model. Our validation set included 43 autonomous vehicles (AV) videos from the publicly available datasets Kitti, A2D2 and PandaSet.
To construct our training pipeline, we first fed the raw, uncompressed video frames into the baseline “teacher” model, the pretrained Depth Anything V2, to generate reference depth maps. We then encoded these original video sequences using Beamr’s Content-Adaptive Bitrate compression (CABR) – achieving 35.2% file size reduction compared to baseline compression across the validation set.
Finally, we used these optimized, compressed frames as the primary input to fine-tune our “student” network, initialized from the “teacher” model pretrained Depth Anything V2. For fine-tuning, we used self-distillation and LoRA fine-tuning. Notably, we used parameter-efficient fine-tuning, updating only ~14% of the total model weights, rather than training the 100 million parameter network from scratch.
Measurement Approach
In real-world AV environments, even uncompressed camera feeds are subject to minor photometric variations (like ISO jitter or thermal noise), as well as mechanical calibration noise (such as subtle horizontal pixel shifts imitating physical camera movements on the vehicle).
Because the “teacher” baseline depth model is highly responsive to these small photometric and geometric shifts, as well as to legitimate small scale variations between frames, its predictions naturally exhibit a baseline variance, even before any compression is applied. Measuring the “student” model against a strict zero-error baseline does not fully capture its practical performance. Instead, a more grounded approach is to evaluate whether the degradation introduced by compression actually exceeds the model’s natural uncertainty under typical sensor and mechanical noise.
To answer this, we contextualized the magnitude of the compression error by measuring the “teacher” model’s noise floor. For each clean validation frame, we generated 30 perturbation variants – combining photometric noise (Gaussian noise, brightness/contrast jitter) with minor geometric shifts (up to 1 horizontal pixel).We then computed the per-pixel standard deviation (σ) of the “teacher” model’s depth predictions across these 30 noisy variants.
Since Depth Anything V2 predicts relative (affine-invariant) depth rather than absolute metric distance (meters), Absolute Relative Error (AbsRel) serves as the primary evaluation metric for this task. It measures the percentage difference between the “student” prediction and the “teacher” baseline, normalizing for scale.
This is vital for AV pipelines: downstream perception stacks use calibration to scale these relative camera depth maps into physical metric distances. By minimizing AbsRel, the “student” model preserves the fundamental 3D geometry, ensuring that downstream metric scaling is safe and accurate.
Experiment Results
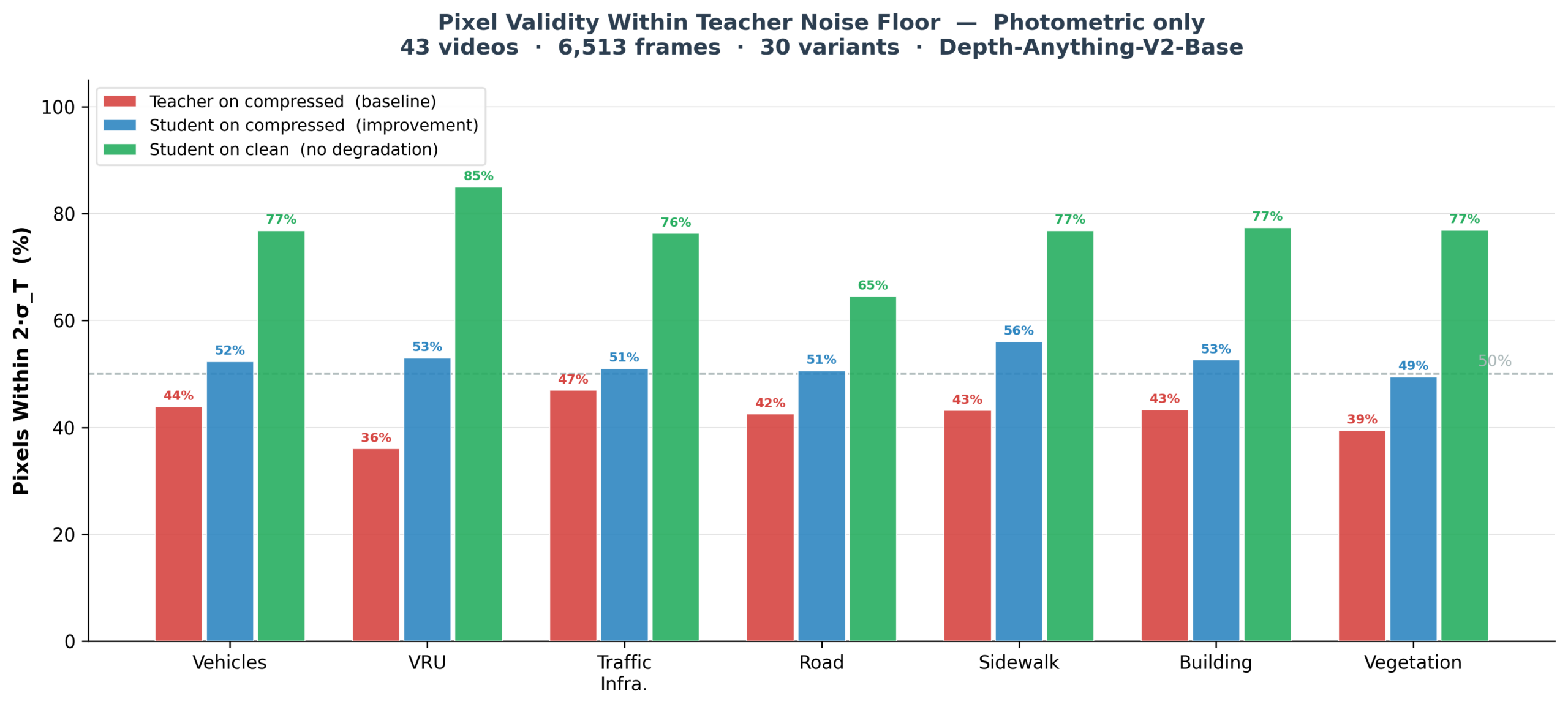
These charts highlight the two most critical technical achievements of the study:
- Safety-Critical Artifact Recovery (Blue > Red): The baseline “teacher” (red) struggles to maintain reliable geometry under compression (compared to “teacher” uncompressed – 100%). “Student” (blue) distinctly improved this.
- No Forgetting (Green > Blue): A critical requirement for AV deployment is that models must not degrade when uncompressed streams are available. “Student” (green) preserved above 70% similarity to target (“teacher” uncompressed – 100%).
The study demonstrated that using compression in the full training pipeline of an AV model can achieve stronger performance, with robustness to compression, enabling improved safety at inference and greater efficiency at training.
Across the validation set, fine-tuning produced consistent improvements at three levels: model stability, geometric restoration, and safety-critical recovery, without compromising clean-input performance:
1. Fine-tuning self-distillation increases model stability: Beyond simply repairing spatial video compression artifacts, utilizing compression as an augmentation mechanism fundamentally stabilizes the overall model.
By lowering the model sensitivity to sensor-like noise, such as gaussian noise, and across all semantic classes – the “student” model’s noise floor (σ_Student) is 15% to 20% lower than the “teacher” model. The LoRA fine-tuning forced the network to learn a more invariant, deterministic geometric representation that is thoroughly robust to natural sensor noise.
2. Global Geometric Restoration: Across every foreground and background class, the “student” model successfully pushed a higher percentage of pixels back into the “teacher” natural 2σ uncertainty band, showing the model neutralized compression artifacts globally rather than merely applying localized algorithmic smoothing.
3. Recovery on safety-critical objects: Vulnerable road users (VRUs), such as pedestrians and motorcyclists, represent the most highly detailed and safety-critical objects in the AV environment, and benefit the most from this methodology. VRUs see the greatest relative recovery from the “student” model, – achieving 30.7% AbsRel reduction.
Under baseline compression, VRUs have the lowest valid pixel rate (36.0%), indicating compression degrades their spatial geometry aggressively. When accounting for realistic mechanical camera vibration, the “student” model with CABR-optimized inputs successfully pushes 74.5% of these compressed pixels safely back into the “teacher” natural 2σ uncertainty band.
4. Preserving clean data: A critical requirement for AV deployment is that models must not degrade when uncompressed streams are available – and mixing raw source frames during training was entirely successful. When evaluated on clean frames, the “student” model’s AbsRel is 2x to 5x lower than its compressed error, and up to 95.5% of its pixels fall comfortably within the “teacher” baseline noise floor.
CABR for AI Development
The study demonstrated that using compression in the full training pipeline of an AI model can achieve stronger performance, with robustness to compression, enabling improved safety at inference and greater efficiency at training. Applying video compression is an essential data augmentation step during model training, improving the model performance with tighter, more accurate depth bounds for downstream perception tasks.
Beamr’s CABR compression complements this methodology directly – with 35.2% file size reduction compared to baseline compression, while the fine-tuned model recovered up to 30.7% of the spatial geometry typically lost on safety-critical objects like vulnerable road users (VRUs). Because CABR is designed to preserve perceptual quality for human viewers, it produces compressed footage that retains the structural detail the training pipeline most needs – making it better suited not just for depth estimation but also for future tasks throughout AI development.
———————–
🤗 Learn more about the research in the Hugging Face article
-> Run Beamr’s ML-safe compression on your own data: beamr.com/autonomous
———————–
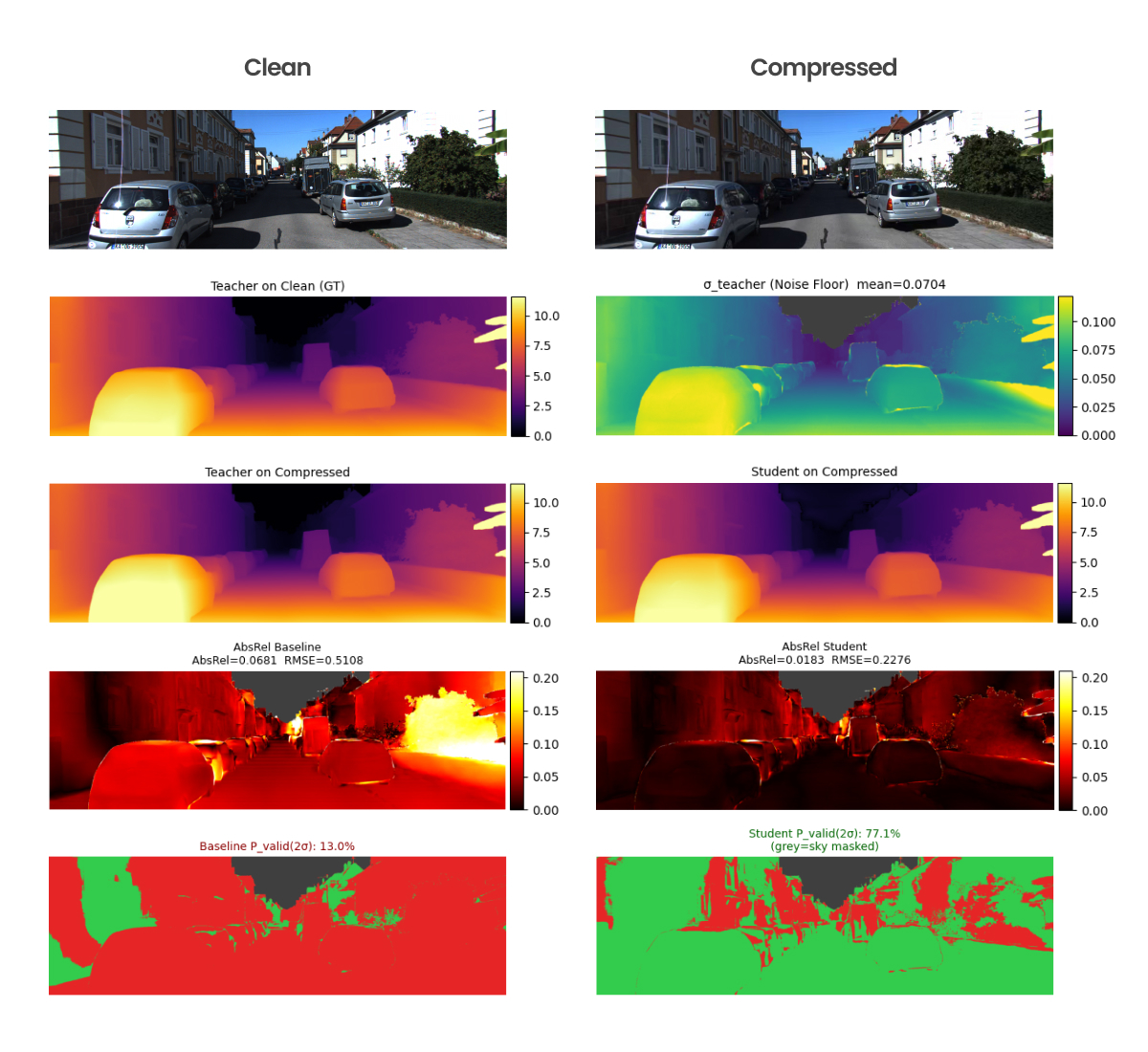
Qualitative visualization of geometric recovery. While the CABR-compressed video (top right) is perceptually identical to the uncompressed frame (top left), it causes spatial degradation in the baseline depth model (left column). This damage is evidenced by the bright AbsRel error heatmaps, which far exceed the model’s natural edge uncertainty shown in the σ_Teacher noise floor map (right, second row). The “student” model (right column) effectively neutralizes these invisible artifacts, darkening the AbsRel error map. By restoring the geometry of the vehicles and street boundaries to operate safely within that natural 2σ noise floor (green mask), the “student” surges the valid pixel rate from 13% to 77.1%.


