Uncategorized15 Min Read Tamar ShohamonMay 28, 2020 Video Codecs in 2020 – The Race is On! Introduction There are several different video codecs available today for video streaming applications, and more will be released this year.…
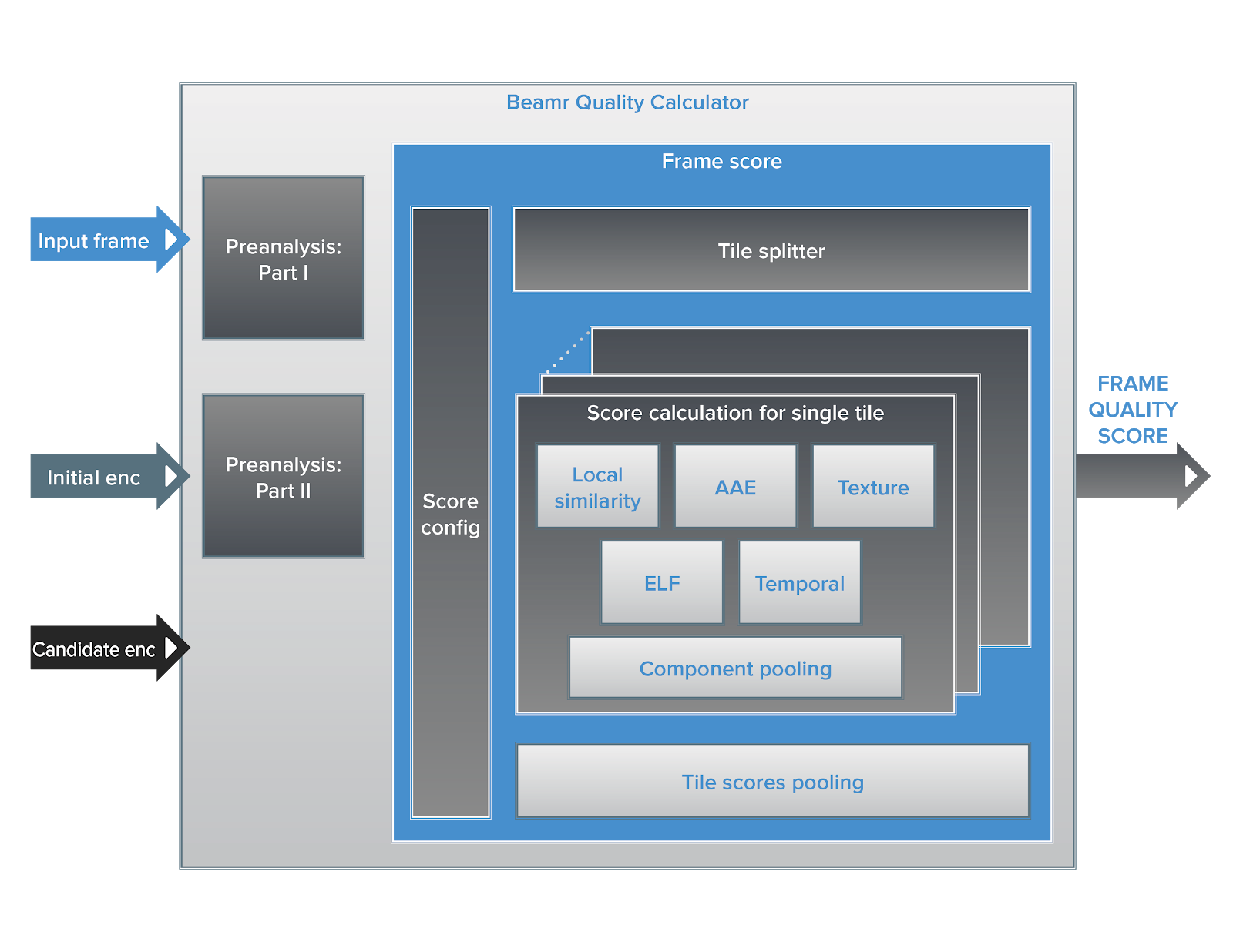
CABR Content-Adaptive quality measure8 Min Read Tamar ShohamonSeptember 11, 2019 The Patented Visual Quality Measure that was Designed to Drive Higher Compression Efficiency At the heart of Beamr’s closed-loop content-adaptive encoding solution (CABR) is a patented quality measure. This measure compares the…
Beamr 5 CABR Content-Adaptive9 Min Read Tamar ShohamonSeptember 11, 2019 A Deep Dive into CABR, Beamr’s Content-Adaptive Rate Control Going Inside Beamr’s Frame-Level Content-Adaptive Rate Control for Video Coding When it comes to video, the tradeoff between quality and…