

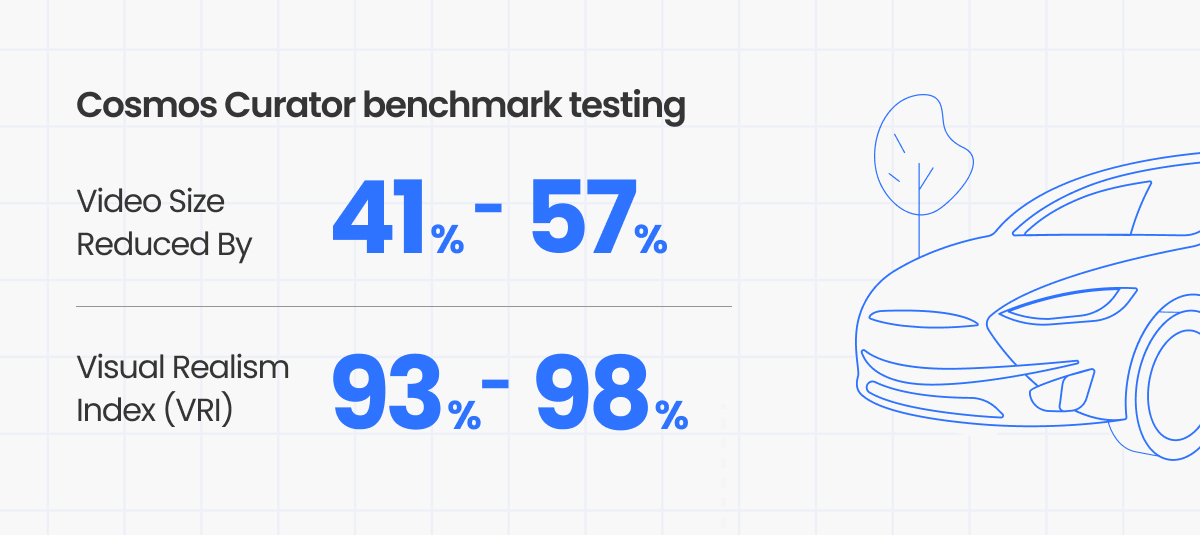
ML-Safe Testing Series, Part 4: 41%–57% file size reduction with no measurable impact on AV captioning for Cosmos Curator outputs
Ronen Nissim, Boris Filippov, Ethan Fenakel
Teams developing Physical AI applications based on NVIDIA’ s open Cosmos platform’s models, libraries and data curation tools such as NVIDIA Cosmos Curator, face a compounding infrastructure challenge: the larger the dataset, the more value the pipeline delivers — and the harder it becomes to store, transfer, and process. Compression becomes essential to scale, but a critical question is whether that compression preserves model accuracy at every stage of the pipeline. Following previous tests that focused on object detection precision, we set out to validate compression for Cosmos Curator’s underlying model outputs.
We tested Beamr’s Content-Adaptive Bitrate (CABR) compression against the default NVENC encoding used in Cosmos Curator’s AV pipeline. The pipeline uses Cosmos-Curator’s AV-pipeline captioning vLLM model, Qwen2.5-VL-7B, a large multimodal model that “watches” video, encodes each frame into visual tokens, and produces natural-language descriptions of the scene. Those descriptions are embedded into high-dimensional vectors that power downstream tasks like search, filtering, and dataset curation.
Our findings: 41%–57% smaller video files with no measurable change to the pipeline’s outputs. Across every metric we tested, compressed and uncompressed videos were indistinguishable.
How We Tested
We evaluated 9 AV video clips from well-known datasets (A2D2, KITTI, PANDAset, and Beamr-proprietary AV footage), spanning diverse scenes, lighting conditions, and bitrate ranges. For each source video, two compressed variants were generated:
- CABR_0: Baseline encoding, using a Quantization Parameter (QP) of 20, similar to Cosmos Curator’s default NVENC configuration.
- CABR_1: CABR-optimized compression, applying Beamr’s content-adaptive bitrate optimization on top of the baseline encode.
To measure how sensitive the AI model is to compression, we needed a reference point. We established this by running the captioning model 50 times on each uncompressed source video using stochastic sampling (with temperature set to 0.7). Each run produces a slightly different caption, and this natural variation defines the model’s “noise floor.” If compression causes less variation than the model produces on its own, compression is effectively invisible.
Captions were evaluated using two independent embedding models: T5-XXL (the native Cosmos Curator embedder) and SBERT as an independent cross-check.
Benchmark Results: Compression is Invisible
1. The Pipeline Reliably Separates Different Videos
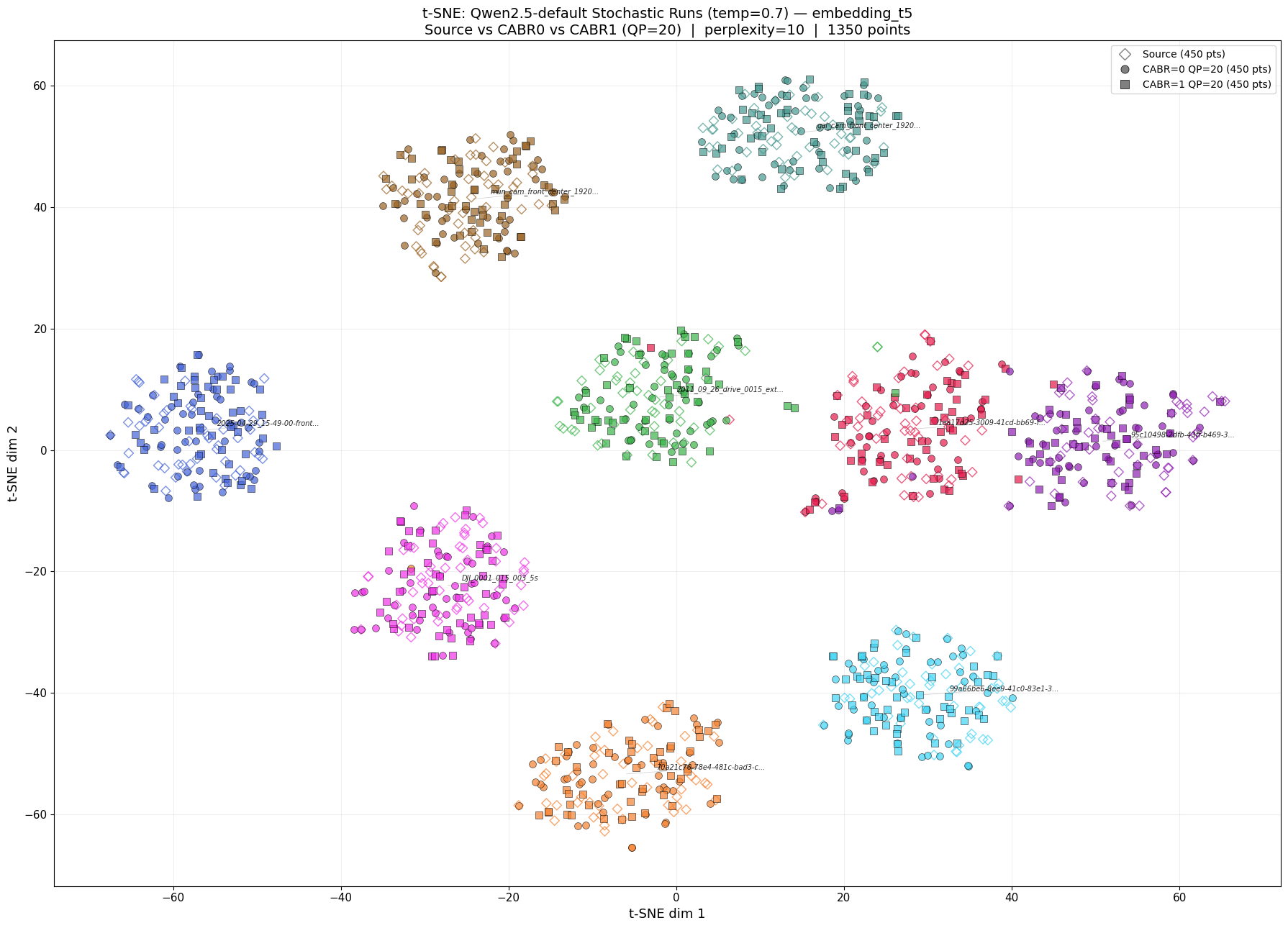
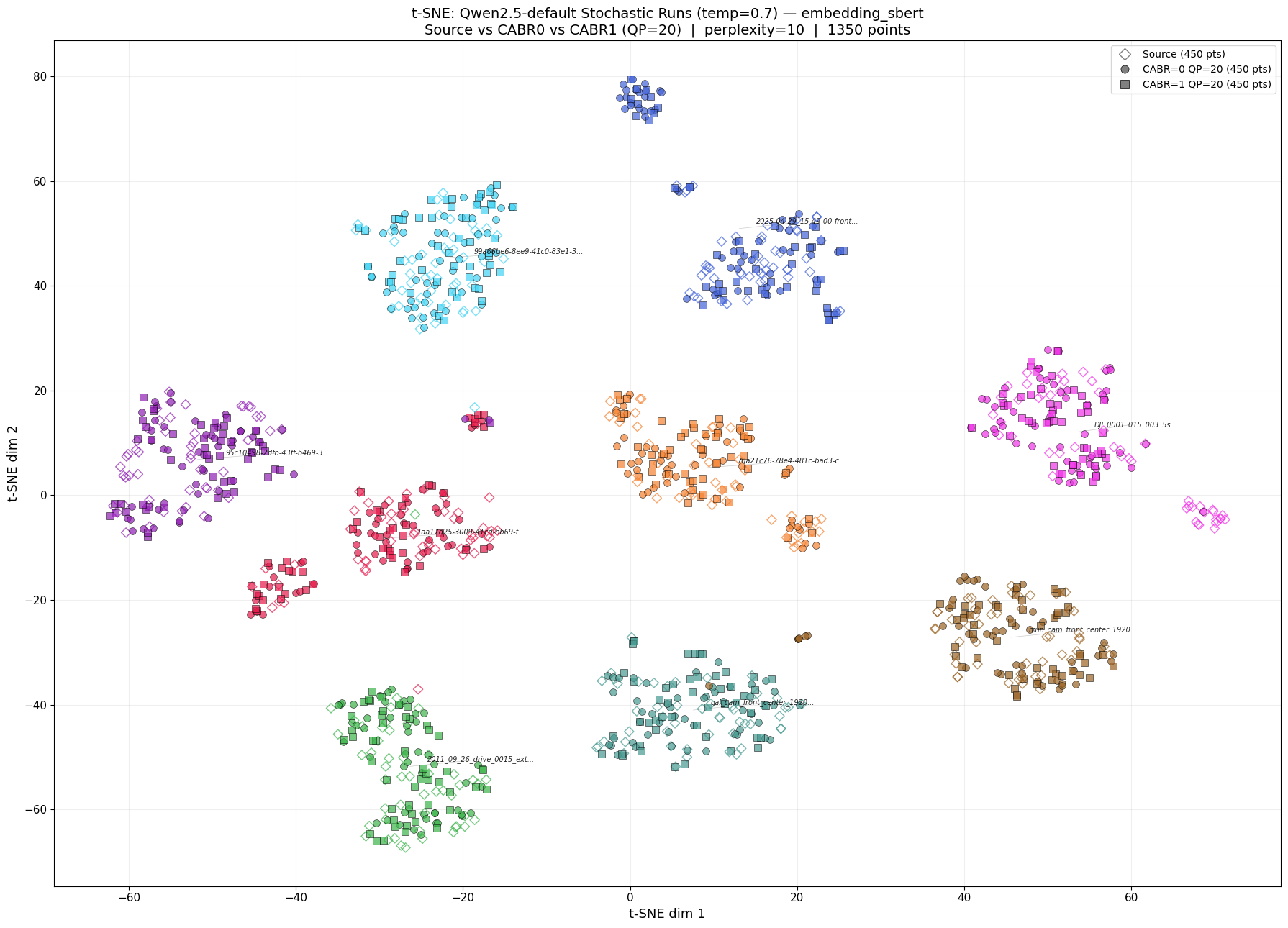
Figure 1: The 9 videos form well-separated clusters of uncompressed source (diamonds), default NVENC (circles), and CABR-optimized (squares), confirming that compression is indistinguishable from the source with t-SNE projection of 1,350 T5-XXL, SBERT caption embeddings (9 videos × 3 variants × 50 stochastic runs at temperature=0.7
Before testing compression, we confirmed that the captioning pipeline can actually tell different videos apart. K-means clustering(*) cleanly separated all nine videos into distinct groups with near-perfect accuracy (ARI > 0.98), and t-SNE visualizations(**) showed each video occupying its own well-separated region in embedding space. Cosine similarity between different videos was consistently lower than similarity within the same video.
This matters because it establishes that the pipeline has enough resolution to detect real content differences. If compression were causing meaningful damage, this system would detect it.
2. Compression Effects Are Dwarfed by Video Differences
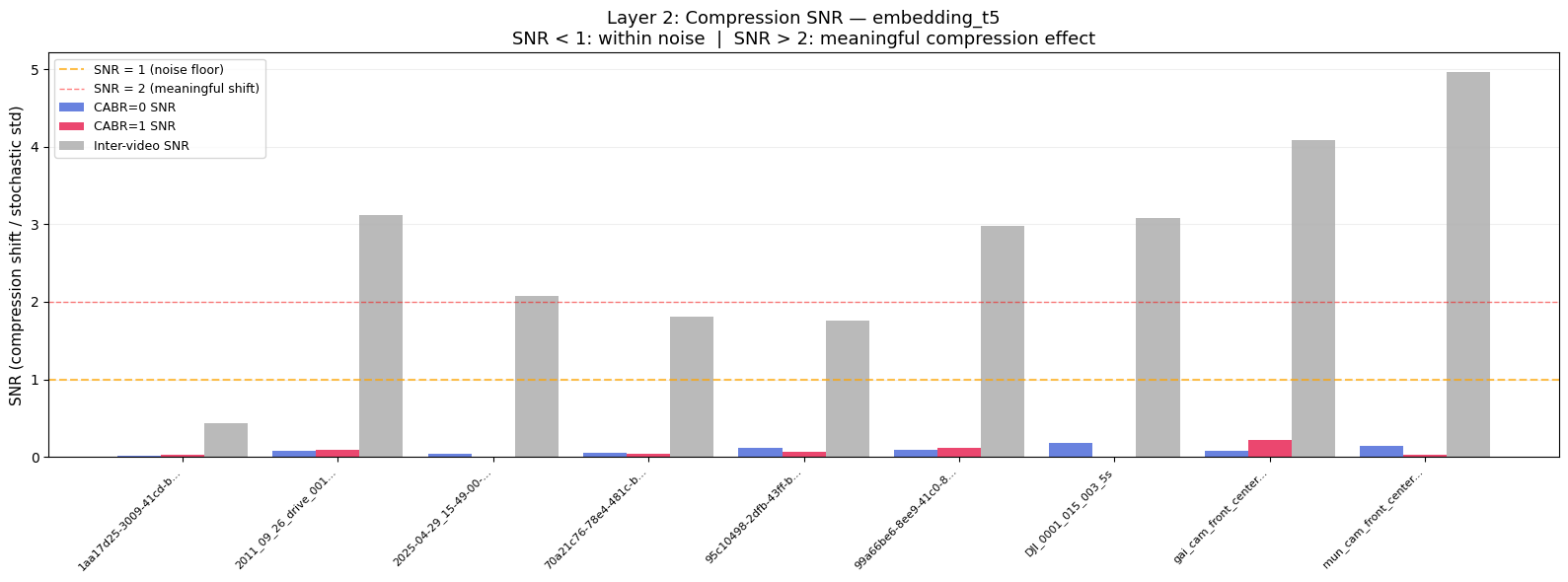
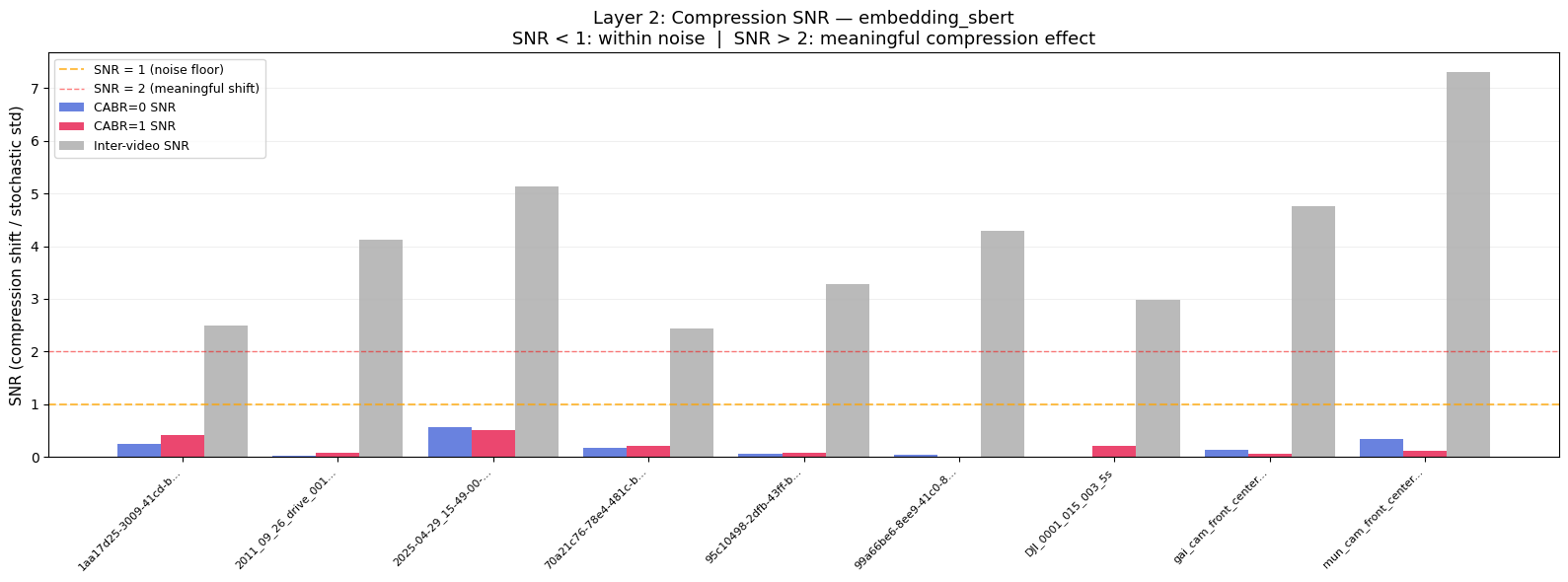
Figure 2: NVENC (CABR0, blue) and CABR (CABR1, red) bars are barely visible, all below 0.25 — well under the SNR=1 noise-floor threshold (orange dashed line) for both T5-XXL, SBERT embeddings. Grey bars show inter-video SNR (0.4–5.0), representing the signal from genuinely different content. The 10–50× gap between compression SNR and inter-video SNR confirms that the model’s own run-to-run randomness dwarfs any effect of compression on model perception.
Next we asked: even if compression causes a small shift, is it large enough to matter? We measured this using Signal-to-Noise Ratio (SNR), which compares the compression-induced embedding shift to the model’s own stochastic variation. Across all nine videos and both embedding models, SNR remained well below 1.0 — meaning the model’s own randomness across repeated runs generates more variation than compression does. Inter-video SNR, by contrast, ranged from 2 to 7 — confirming that genuine content differences are easily detected while compression effects remain buried in the noise.
3. The Pipeline Can’t Differentiate Compressed from Uncompressed
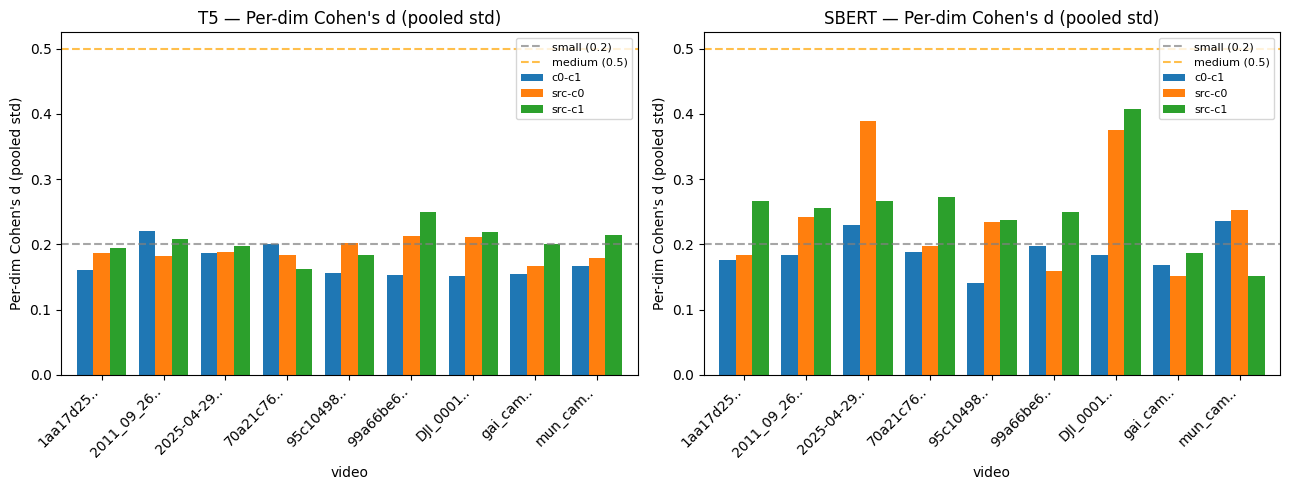
Figure 3: Centroid shift analysis — measuring compressed vs. source similarity. Compression barely moves the caption embeddings. Each bar measures how much compression shifts the average caption embedding compared to the model’s own noise. Below the grey line (0.2) means the compression effect is negligible; below 0.5 the effect is small and essentially adds no meaningful impact.
Finally, the strongest finding: within each video, the pipeline simply cannot tell compressed from uncompressed. Pairwise cosine similarity between source and compressed variants was statistically identical to similarity within the source runs themselves. K-means(*) assigned at least 96% of all runs — source, CABR0, and CABR1 — to the same cluster for every video. t-SNE(**) qualitatively confirmed that compressed variants clustered within their source video’s stochastic cloud rather than forming separate groups.
Centroid shift analysis(***) reinforced this: the average embedding of compressed runs drifts from the source average by just 0.2 standard deviations per dimension (Cohen’s d) — well below the threshold for even a “small” effect. The compressed centroid sits well inside the source distribution, 4–7 times closer to its own source than to any other video.
This held for structured scene understanding as well. To complement the free-form caption analysis we also evaluated the model using the “Visual Realism Index” (VRI): a 45-field structured classification covering infrastructure, traffic conditions, and fine visual details. Unlike open-ended captions, VRI poses specific questions with strict multiple-choice answers, allowing direct field-by-field comparison without the need for semantic encoding. Agreement rates between uncompressed source, default NVENC, and CABR-optimized variants remained between 88.9% and 100% across all tested videos, with no systematic degradation. In several cases, the CABR-optimized variant matched the source more closely than default compression.
*K-means clustering indicates whether compression variants affect our ability to differentiate between videos.
**t-SNE visualization qualitatively assesses clustering behavior across videos and compression variants.
***Centroid shift analysis, estimates how far the mean embedding of each compressed variant (NVENC, CABR) drifts from the source mean, relative to the source distribution’s own spread. This complements the pairwise cosine similarity analysis by operating directly in the full embedding space rather than on scalar similarity values.
What This Means
The conclusion is consistent across every method: The compression-induced changes are negligible in absolute terms, invisible to clustering algorithms, and overwhelmed by both the model’s own stochastic variation and the natural separation between different videos. Any downstream task consuming these embeddings — search, filtering, deduplication, or dataset curation — would produce identical results on compressed and uncompressed video.
For physical AI teams working with autonomous vehicles, robotics, and smart spaces, this means content-adaptive compression can reduce storage, delivery, and I/O costs at scale, without trading off the accuracy of the AI systems that depend on the data.
———————–
Integrate ML-Safe Video Data Processing in Your Workflow Let’s Talk>>
———————–

Learn more in our ML-Safe AV Video Data Testing series:
Part 1: Beamr is Pushing the Boundaries of AV Data Efficiency, Accelerated by NVIDIA
Part 2: ML-Safe AV Video Data Processing Achieves Up to 50% Storage Reduction
Part 3: Deep Dive: Managing the Petabyte-Scale AV Video Data Bottlenecks


