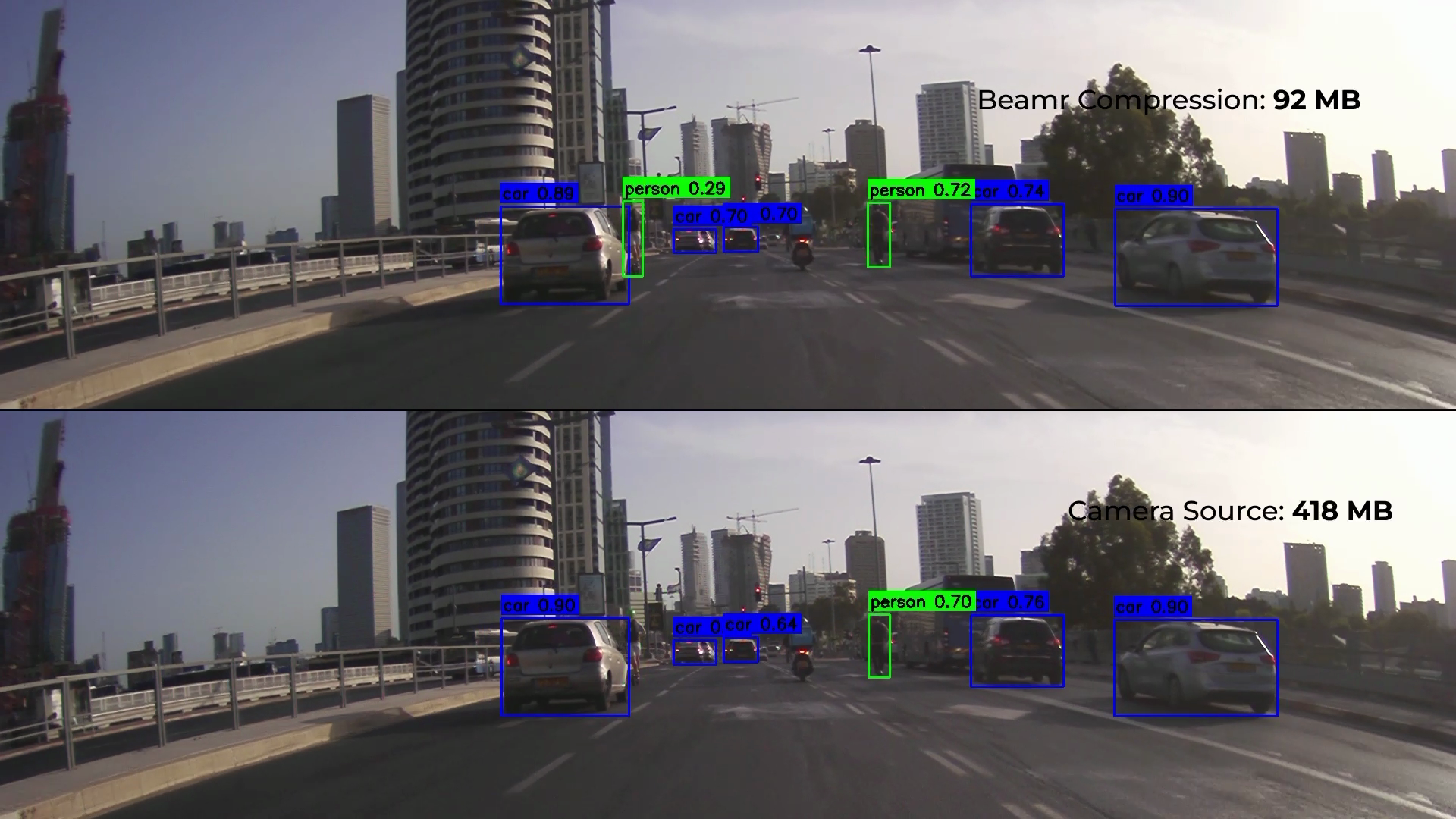
ML-Safe Testing Series, Part 3: Optimized video data processing for AV – 20%-50% file size reduction with remarkable detection, localization and confidence consistency · By Ethan Fenakel and Ronen Nissim
When Autonomous vehicle (AV) and ML engineers confront the escalating petabyte-scale data challenges, their instinct is often to minimize compression: store video with maximum fidelity to ensure algorithms capture every critical detail. But such a conservative approach creates its own crisis – infrastructure bottlenecks, development delays, and exponential costs. Generic compression methods, such as fixed-parameter or uniform compression, don’t solve the problem either, as they often under-compress (wasting storage), or over-compress (degrading ML model accuracy).
The result is a triple constraint that keeps tightening:
- Scale – Managing rapid data growth, with tens to hundreds of petabytes per company.
- Fidelity – Preserving the information the models need.
- Future-proofing – Ensuring datasets remain valid as architectures evolve. What if the processing that works for today’s detection models breaks something in the next system?
Beamr has validated (ML-safe series, part 1) that video data file size reduction by up to 50% while preserving model accuracy is possible, when using a content-adaptive approach that overcomes the risk of degrading model precision, created by generic video compression. The patented Content-Adaptive bitrate (CABR) technology scans data frame-by-frame for ML-safe optimization that frees up essential storage, networking and compute resources. Beamr’s technology has been incorporated into successful Proof-of-Concepts with leading AV teams.

Beamr’s AV video data processing directly translates to lower storage costs, faster data transfer, and accelerated ML training cycles. All that, with a low-risk path for AV and ML teams.
Beamr’s Optimization vs Encoded Video Data
In our previous benchmark testing (ML-Safe series, part 2), we validated Beamr’s compression against uncompressed source video, demonstrating preservation of object detection accuracy – a foundational task for AV perception systems. Part 3 takes the next step: testing optimized re-encoding with Beamr compared with already-encoded video data.
To further validate the technology, we compared Beamr’s content-adaptive optimization against NVIDIA’s recently published physical AI AV dataset – an already encoded dataset. We examined whether additional compression is possible without degrading model performance. Testing showed 20%-50% file size reduction, while preserving the model’s output with remarkable fidelity across detection, localization, and confidence consistency.
Experiment Setup
We designed benchmark testing with NVIDIA’s dataset, and tested randomly sampled 600 videos. We ran both the encoded dataset videos and the optimized videos by Beamr’s CABR into RF-DETR (Medium), a state-of-the-art transformer-based object detector. Similarly to Part 2, also in Part 3, the validation focused on object detection, using the COCO evaluation protocol.
To ensure computational efficiency while maintaining temporal consistency, we evaluated every 4th frame from each video. Since the dataset lacks ground truth annotations of objects, we treated the encoded dataset outputs as pseudo-ground truth labels, and aimed for the compressed video detection outputs to be consistent with those labels. To ensure we only used valid detected objects, we filtered out objects with confidence scores lower than 0.5 for both the encoded dataset videos and the Beamr’s optimized outputs.
We looked to answer the key question: How close are the predictions on the Beamr-optimized videos to the predictions on the original? For that, we evaluated them across three complementary dimensions: Detection consistency, Localization consistency, and Confidence consistency.
Detection consistency
To measure detection-level consistency, we used the source model’s predictions as pseudo ground truth. This method captures both classification agreement and bounding-box overlap quality.
Results showed strong preservation of detection performance, with mean average precision (mAP) of 0.96 indicating near-identical results:
Mean Average Precision (mAP): 0.96 [IoU 0.50-0.95 | area = all | maxDets=100]
In practice, we see that RF-DETR’s outputs on the Beamr-encoded videos fall extremely close to those on the original, demonstrating strong semantic and structural alignment.
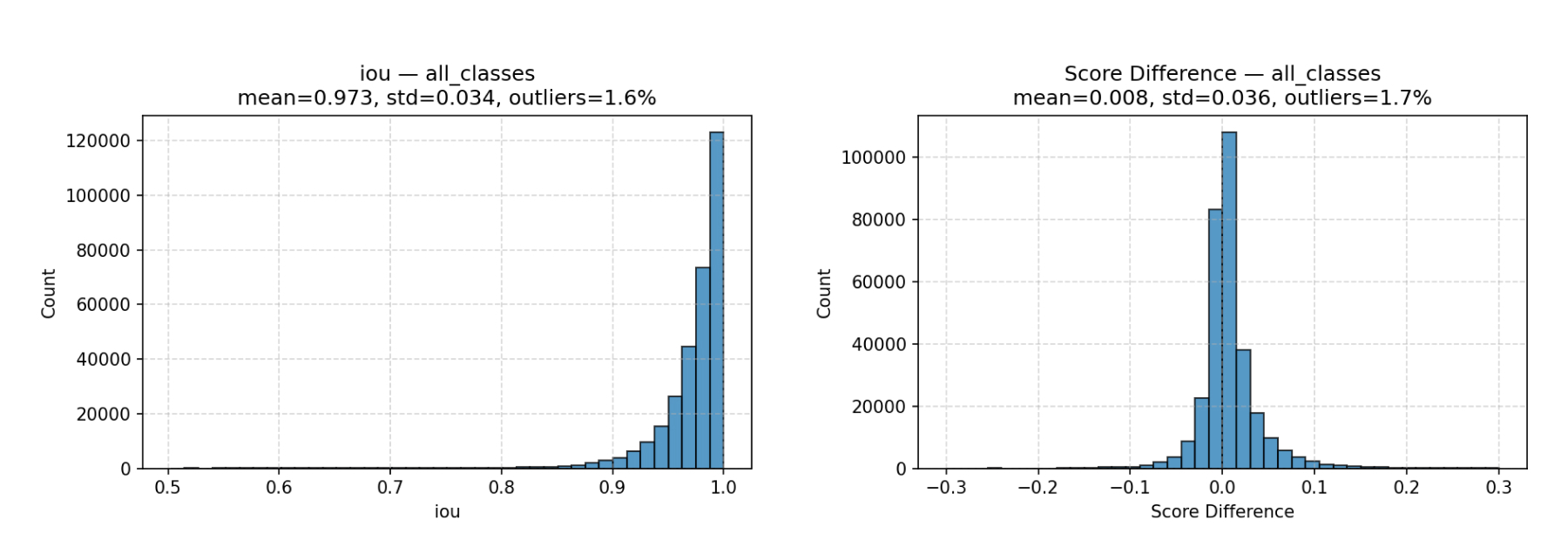
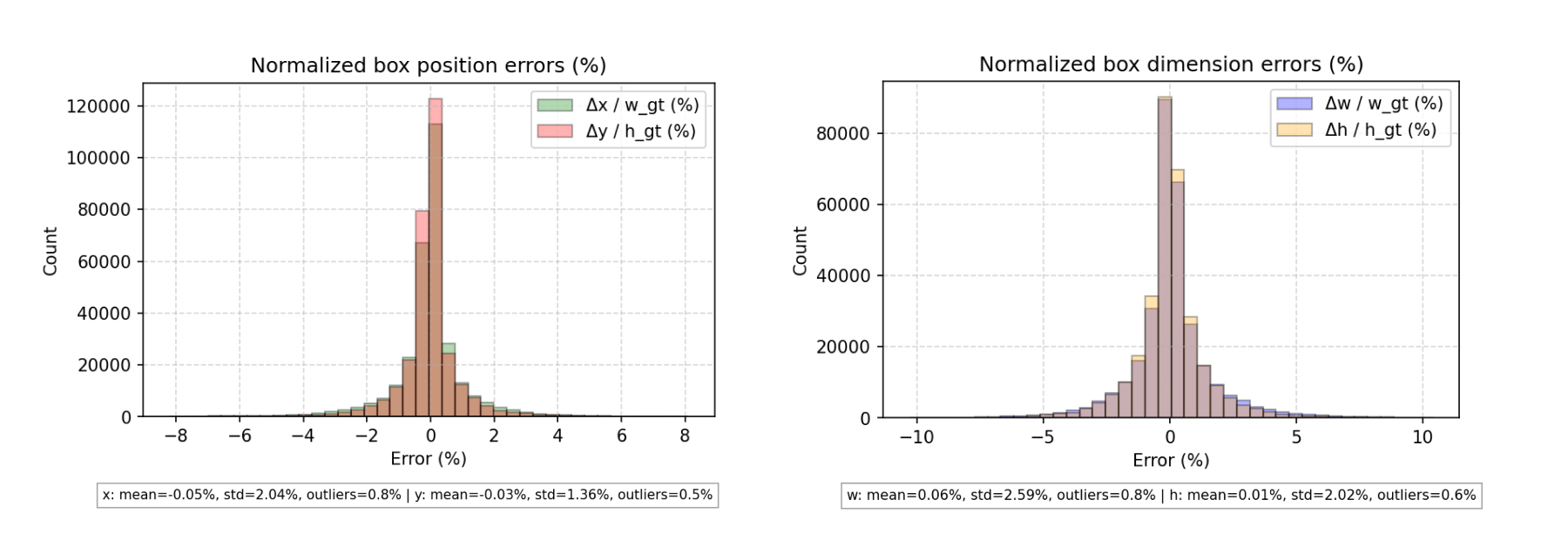
Localization consistency
While mAP captures correct detections, we also analyze finer-grained localization stability. For each matched detection between the two model runs, we computed the differences in bounding-box regression outputs: Δx, Δy, Δwidth, Δheight, IoU. These values form a distribution that reveals how much (or how little) compression shifts object boundaries.
We found that the distributions remain tightly centered and narrow, showing minimal pixel-level deviation and confirming that Beamr preserves structural cues required for accurate localization.
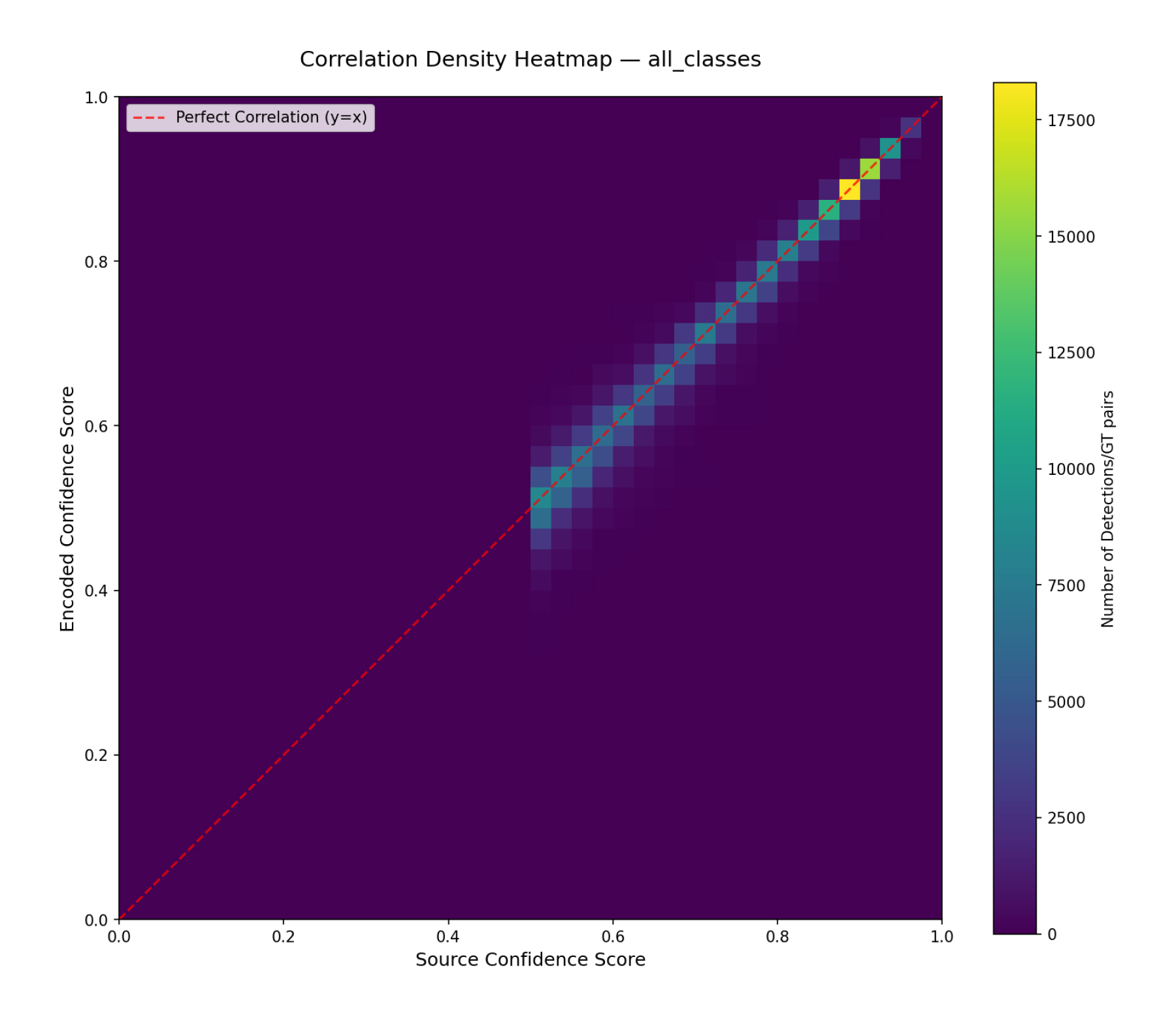
Confidence consistency
Confidence scores represent how certain the model is about each detection – a critical input for downstream components such as tracking, fusion, and decision-making. To evaluate whether Beamr’s compression affects the model’s perceived certainty, we analyzed Confidence score differences and Score error distributions.
We performed a correlation test of the objects’ confidence score, showing that Beamr’s optimized videos predictions have confidence scores which highly correlate with the dataset videos confidence scores predictions. Most detections appear to have >0.9 confidence for objects found in the dataset videos and the optimized videos.
As expected, the lower the source object confidence, the larger the confidence difference with the compressed output (denoted in the arrow-head shape of the confidence correlation density map above). For a common confidence score of 0.8 and above, the variance observed is very low. The score difference distribution, and specifically the <1% score difference, shows that there is no systematic degradation of confidence in the optimized vs the dataset videos and that it is mostly random.
The result suggests the model – whose architecture, RF-DETR, is well known and used – could be a good proxy for comparison with a well fine-tuned similar object detection model employed by AV companies.
Paired with the general high confidence in values for both source and compressed detected objects, the low difference variance at high confidence values, and the remarkably high mIoU (~0.97) and mAP (0.96) – we notice no distinct difference between encoded and re-encoded videos evaluated and the ~200k detected objects.
The Impact on AV and ML
This testing validated 20%-50% file size reduction while maintaining the data fidelity required for safety-critical autonomous driving systems and ML model performance – also when comparing encoded videos to Beamr’s optimized videos.
Across detection, localization, and confidence metrics, we found:
- Precision (mAP) remains consistently high, indicating that detections and classifications align closely.
- Localization differences are minimal, confirming that bounding-box structure is preserved.
- Confidence scores remain highly correlated, demonstrating stable model behavior.
Unlike fixed-parameter or uniform compression methods, Beamr’s content-adaptive compression allocates bits dynamically based on scene complexity and object importance, and preserves perceptual and structural details that matter for ML models. The result is a codec that is semantically aware, optimized for ML robustness, deterministic and consistent, and efficient at scale.
This directly translates to lower storage costs, faster data transfer, and accelerated ML training cycles. All that, with a low-risk path for AV and ML teams.
———————–
Drowning in video data? Discover ML-safe AV video data processing. Let’s Talk>>
———————–
Learn more in our ML-Safe AV Video Data Testing series:
Part 1: Beamr is Pushing the Boundaries of AV Data Efficiency, Accelerated by NVIDIA
Part 2: ML-Safe AV Video Data Processing Achieves Up to 50% Storage Reduction